Go 博客
Go 的垃圾回收器之旅:起步
这是我于2018年6月18日在国际内存管理会议(ISMM)上发表的主题演讲的文字记录。在过去的25年里,ISMM一直是发布内存管理和垃圾回收论文的首选场所,我很荣幸能受邀发表演讲。
摘要
Go 语言的特性、目标和用例迫使我们重新思考整个垃圾回收机制,并将我们带到了一个令人惊讶的境地。这段旅程令人振奋。本次演讲将描述我们的旅程。这是一段由开源和谷歌生产需求驱动的旅程。我们还将会探讨一些走入死胡同的“峡谷”,但数字最终指引了我们回家。本次演讲将深入探讨我们旅程的“如何”和“为什么”,我们在2018年的现状,以及 Go 为旅程的下一段所做的准备。
简介
Richard L. Hudson (Rick) 以其在内存管理方面的工作而闻名,包括发明了 Train、Sapphire 和 Mississippi Delta 算法以及 GC 栈映射,这些技术使得在 Modula-3、Java、C# 和 Go 等静态类型语言中能够进行垃圾回收。Rick 目前是谷歌 Go 团队的一员,负责 Go 的垃圾回收和运行时问题。
联系方式: rlh@golang.org
评论: 请参阅 golang-dev 上的讨论。
文字记录

我是 Rick Hudson。
这是一场关于 Go 运行时,特别是垃圾回收器的演讲。我准备了大约45到50分钟的材料,之后将有时间进行讨论,我也会在场,所以欢迎大家会后过来交流。

在开始之前,我想感谢一些人。
演讲中很多精彩的内容都出自 Austin Clements 之手。来自剑桥 Go 团队的 Russ、Than、Cherry 和 David 是一群令人兴奋且有趣的工作伙伴。
我们还要感谢全球160万 Go 用户,他们为我们提供了有趣的问题来解决。没有他们,很多问题就不会浮出水面。
最后,我要感谢 Renee French,感谢她多年来创作的这些可爱的 Gophers。在演讲中你会看到好几个。

在我们深入探讨这些内容之前,我们真的需要看看 GC 眼中的 Go 是什么样子的。

首先,Go 程序拥有数十万个栈。它们由 Go 调度器管理,并且总是在 GC 安全点被抢占。Go 调度器将 Go 程复用(multiplex)到 OS 线程上,通常一个 OS 线程对应一个硬件线程。我们通过复制栈并更新栈中的指针来管理栈及其大小。这是一个局部操作,因此扩展性相当好。

接下来重要的是 Go 是一种面向值(value-oriented)的语言,遵循 C 风格系统语言的传统,而不是大多数托管运行时语言的面向引用(reference-oriented)语言的传统。例如,这展示了 `tar` 包中的一个类型在内存中的布局。所有字段都直接嵌入在 `Reader` 值中。这使得程序员在需要时可以更好地控制内存布局。可以将相关的字段放在一起,这有助于提高缓存局部性。
面向值也有助于外部函数接口(FFI)。我们拥有与 C 和 C++ 的快速 FFI。显然,谷歌拥有大量可用设施,但它们是用 C++ 编写的。Go 迫不及待地想用 Go 重新实现所有这些东西,所以 Go 必须通过外部函数接口访问这些系统。
这个设计决策导致了运行时中一些非常了不起的事情。它可能是 Go 与其他 GC 语言最显著的区别。
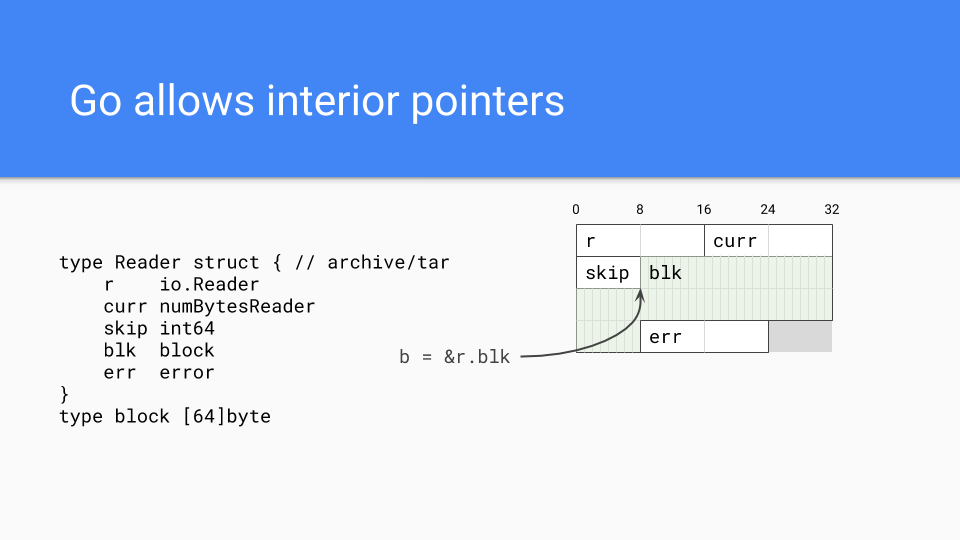
当然,Go 可以拥有指针,事实上它们可以拥有内部指针。这类指针会使整个值保持活跃,并且相当常见。

我们还有一个提前编译系统,所以二进制文件包含了整个运行时。
没有 JIT 重编译。这有利有弊。首先,程序执行的可复现性大大提高,这使得编译器改进的进展更快。
另一方面,我们无法像 JIT 系统那样进行反馈优化。
所以有利有弊。

Go 提供了两个控制 GC 的“旋钮”。第一个是 `GCPercent`。本质上,它是一个用来调整 CPU 使用量和内存使用量的旋钮。默认值为 100,这意味着堆的一半用于存放活动内存,一半用于分配。你可以向任一方向调整它。
`MaxHeap`(尚未发布,但正在内部使用和评估)允许程序员设置最大堆大小。内存不足 (OOM) 对 Go 来说是棘手的;内存使用量的暂时性峰值应该通过增加 CPU 成本来处理,而不是通过中止。基本上,如果 GC 检测到内存压力,它会通知应用程序应该卸载负载。一旦情况恢复正常,GC 会通知应用程序可以恢复正常负载。`MaxHeap` 还提供了更大的调度灵活性。运行时不再总是担心可用内存量,而是可以将堆大小扩展到 `MaxHeap`。
以上是我们对 Go 中与垃圾回收器相关的部分进行的讨论。

现在,让我们来谈谈 Go 运行时,以及我们是如何走到今天这一步的。

那是 2014 年。如果 Go 不能以某种方式解决 GC 延迟问题,那么 Go 就不会成功。这一点很明确。
其他新兴语言也面临着同样的问题。Rust 等语言选择了不同的道路,但我们将讨论 Go 所走的道路。
为什么延迟如此重要?

数学上对此毫无通融之处。
99%ile 的独立 GC 延迟服务等级目标(SLO),例如 GC 周期 99% 的时间小于 10ms,根本无法扩展。重要的是整个会话期间或一天中多次使用应用程序时的延迟。假设一个浏览了多个网页的会话,在会话期间进行了 100 次服务器请求,或者进行了 20 次请求,并且一天中有 5 个这样的会话。在这种情况下,只有 37% 的用户在整个会话中都能获得一致的低于 10ms 的体验。
如果我们建议 99% 的用户获得低于 10ms 的体验,数学表明您实际上需要瞄准 4 个 9,即 99.99%ile。
所以,那是 2014 年,Jeff Dean 刚刚发布了他的论文《The Tail at Scale》,这篇文章对此进行了更深入的探讨。由于其对谷歌未来的严重影响以及谷歌的扩展规模,这篇论文在谷歌被广泛阅读。
我们将这个问题称为“9 的暴政”。

那么,如何对抗“9 的暴政”呢?
在 2014 年,人们已经做了很多事情。
如果你想要 10 个答案,就多问几个,然后取前 10 个,将这些答案放在搜索页面上。如果请求超过 50%ile,就重新发出请求或将其转发给另一个服务器。如果 GC 即将运行,就拒绝新请求或将请求转发给另一个服务器,直到 GC 完成。依此类推。
所有这些变通方法都源于非常有才华的人们面临的非常真实的问题,但它们并没有解决 GC 延迟的根本问题。在谷歌的规模下,我们必须解决根本问题。为什么?

冗余无法扩展,冗余成本高昂。它需要新的服务器场。
我们希望能够解决这个问题,并将其视为改进服务器生态系统的机会,同时保护一些濒危的玉米地,让一粒玉米有机会在七月四日达到膝盖高,并充分发挥其潜力。

这是 2014 年的 SLO。是的,事实是我故意保守了目标,我刚加入团队,对我来说这是一个新流程,我不想过度承诺。
此外,关于其他语言中 GC 延迟的演示简直太可怕了。

最初的计划是做一个无读屏障的并发复制 GC。那是长远计划。人们对读屏障的开销存在很大的不确定性,因此 Go 希望避免使用它们。
但在 2014 年的短期内,我们必须团结起来。我们必须将所有运行时和编译器都转换为 Go 语言。当时它们是用 C 编写的。不再有 C,不再有由于 C 程序员不理解 GC 但对如何复制字符串有奇思妙想而导致的长期 bug。我们还需要快速得到一些东西,并专注于延迟,但性能损失必须小于编译器带来的提速。所以我们受到限制。我们基本上只有一年的编译器性能提升空间,可以被 GC 并发所抵消。但仅此而已。我们不能减慢 Go 程序的运行速度。在 2014 年,这将是不可容忍的。

所以我们稍作退让。我们不打算进行复制部分。
决定采用三色并发算法。在我职业生涯的早期,我和 Eliot Moss 进行了期刊证明,证明了 Dijkstra 算法可以与多个应用程序线程协同工作。我们还证明了可以消除 STW(Stop The World)问题,并且有证明可以做到。
我们还担心编译器速度,即编译器生成的代码。如果大部分时间保持写屏障关闭,对编译器优化的影响将最小,编译器团队可以快速推进。Go 在 2015 年也迫切需要短期成功。
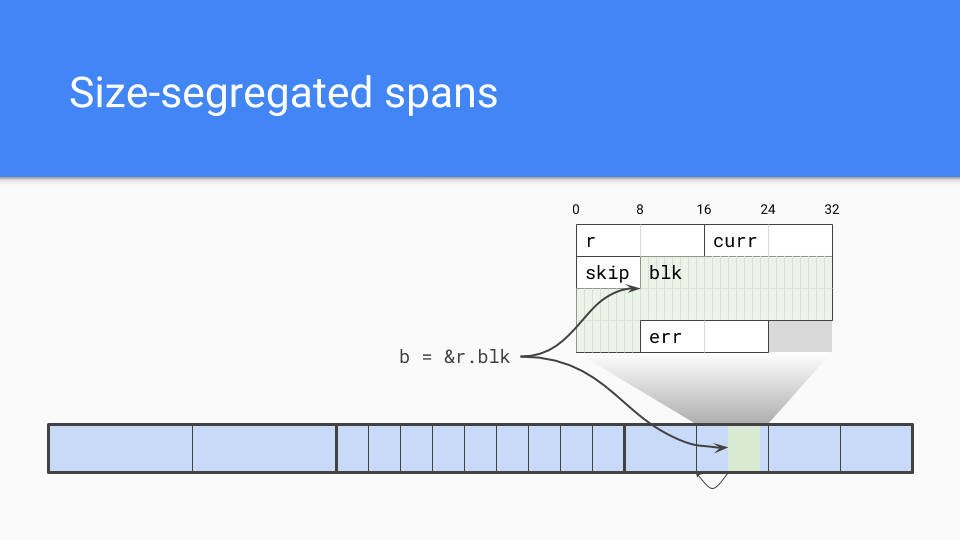
那么,让我们来看看我们做的一些事情。
我们采用了按大小划分的 Span(span)。内部指针是个问题。
垃圾回收器需要有效地找到对象的起始位置。如果知道 Span 中对象的大小,它只需向下取整到该大小,那就是对象的起始位置。
当然,按大小划分的 Span 还有其他优点。
低碎片化:根据 C 的经验,以及谷歌的 TCMalloc 和 Hoard,我曾深入参与 Intel 的 Scalable Malloc,这项工作让我们有信心,碎片化不会成为非移动分配器的问题。
内部结构:我们完全理解并有经验。我们知道如何进行按大小划分的 Span,如何进行低争用或零争用的分配路径。
速度:非移动不让我们担心,分配速度可能有所放慢,但仍在 C 的数量级。可能不如指针推进(bump pointer)快,但还可以接受。
我们还有外部函数接口问题。如果我们不移动对象,那么在尝试固定对象并将间接层放在 C 和正在处理的 Go 对象之间时,我们就不必处理移动收集器可能遇到的长期 bug。

下一个设计选择是将对象的元数据放在哪里。由于没有头部,我们需要一些关于对象的信息。标记位(Mark bits)保存在旁边,用于标记和分配。每个字(word)有 2 位与之关联,用来告诉您该字是标量(scalar)还是指针。它还编码了对象中是否还有更多指针,这样我们就可以更快地停止扫描对象。我们还有一个额外的位编码,可以用作额外的标记位或用于其他调试。这对启动和查找 bug 非常有价值。

那么,写屏障(write barrier)呢?写屏障仅在 GC 期间开启。其他时候,编译后的代码会加载一个全局变量并查看它。由于 GC 通常是关闭的,硬件会正确地预测并绕过写屏障。当我们处于 GC 状态时,该变量不同,写屏障负责确保在三色操作期间不会丢失任何可达对象。

代码的另一部分是 GC Pacer。这是 Austin 完成的一些很棒的工作。它基本上基于一个反馈循环,该循环确定何时最佳地启动 GC 周期。如果系统处于稳定状态而不是处于阶段变化中,标记将在内存耗尽时结束。
情况可能并非如此,因此 Pacer 还必须监控标记进度,并确保分配不会超过并发标记。
如有必要,Pacer 会减慢分配速度,同时加快标记速度。在高层次上,Pacer 会暂停大量分配的 Goroutine,并让其进行标记工作。工作量与 Goroutine 的分配量成正比。这会加速垃圾回收器,同时减慢变异器(mutator)。
完成所有这些后,Pacer 会将其从当前 GC 周期和之前的周期中学到的知识用于预测何时启动下一个 GC。
它做得远不止这些,但这只是基本方法。
数学绝对引人入胜,请联系我获取设计文档。如果您正在开发并发 GC,您绝对应该看看这些数学原理,看看是否与您的数学原理相同。如果您有任何建议,请告诉我们。
*Go 1.5 并发垃圾回收器 Pacing 和 提案:区分软堆限制和硬堆限制

是的,我们取得了成功,很多成功。一个年轻、更疯狂的 Rick 会把这些图表纹在我的肩膀上,因为我太自豪了。
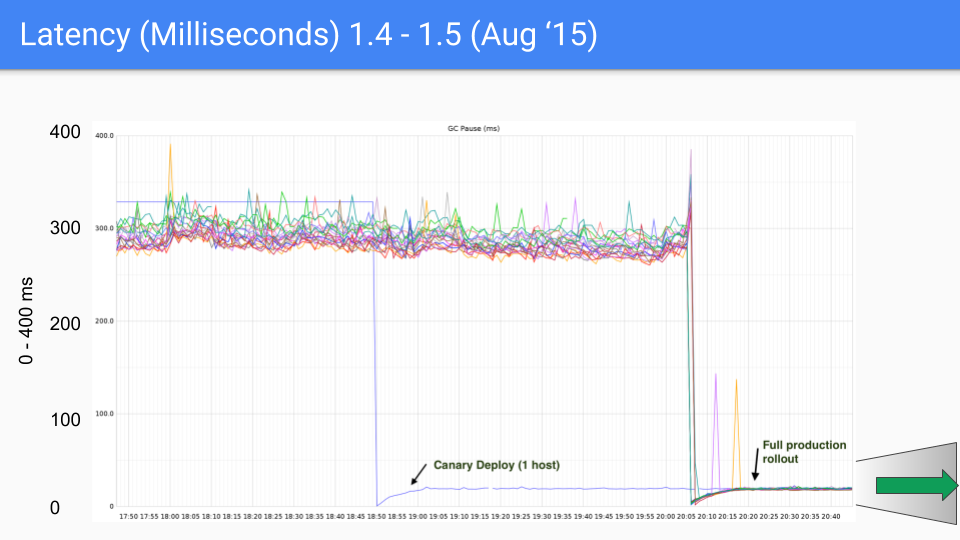
这是一系列为 Twitter 生产服务器绘制的图表。当然,我们与该生产服务器无关。Brian Hatfield 进行了这些测量,并意外地在 Twitter 上发布了它们。
Y 轴是 GC 延迟(毫秒)。X 轴是时间。每个点都是该 GC 期间的“停止世界”(stop the world)暂停时间。
在我们 2015 年 8 月的第一个版本中,我们看到延迟从大约 300-400 毫秒下降到 30-40 毫秒。这很好,数量级上有了很大提升。
我们将 Y 轴从 0 到 400 毫秒大幅度地改为 0 到 50 毫秒。
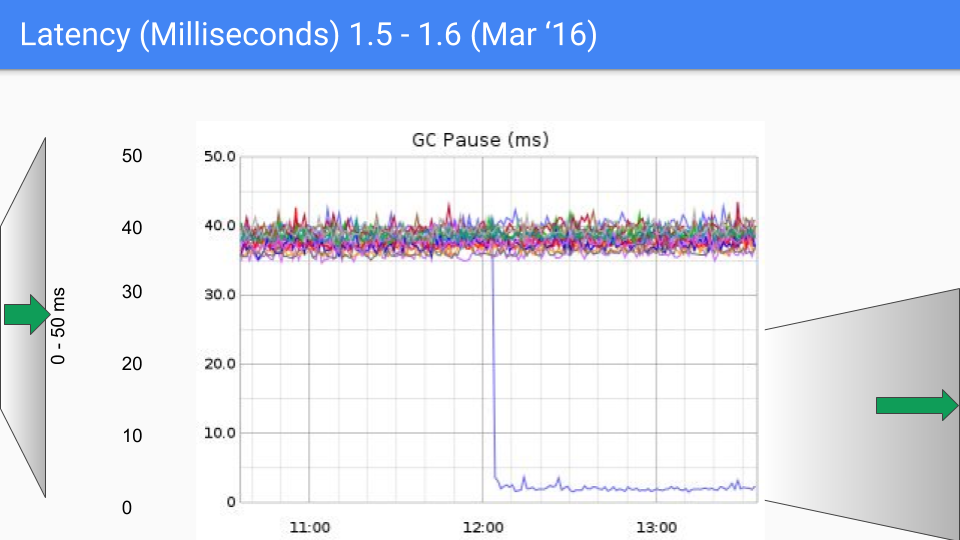
这是 6 个月后。这次改进主要是由于系统性地消除了我们在“停止世界”期间进行的所有 O(heap) 操作。这是我们第二次数量级改进,从 40 毫秒下降到 4-5 毫秒。
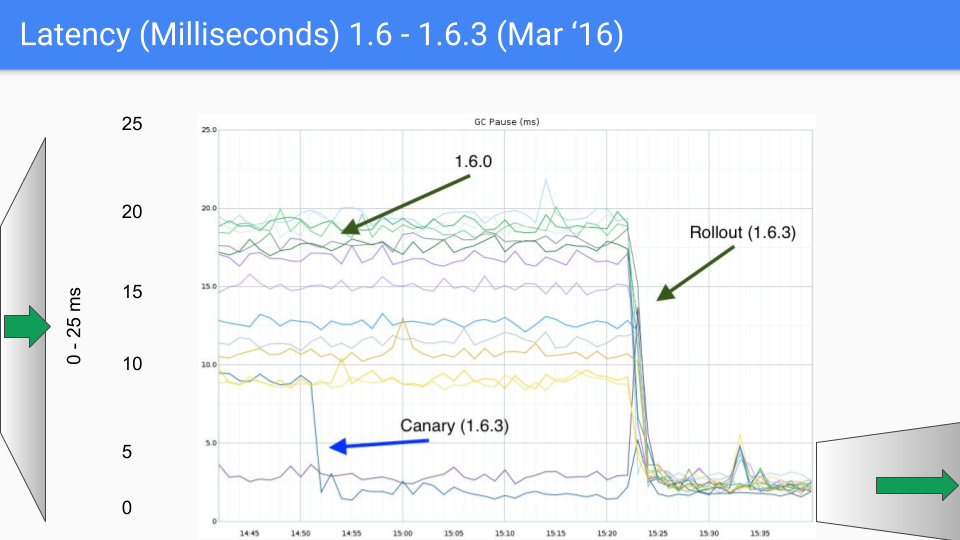
其中存在一些 bug 需要修复,我们在次要版本 1.6.3 中完成了这些工作。这将延迟降低到远低于 10 毫秒,达到了我们的 SLO。
我们即将再次更改 Y 轴,这次改为 0 到 5 毫秒。
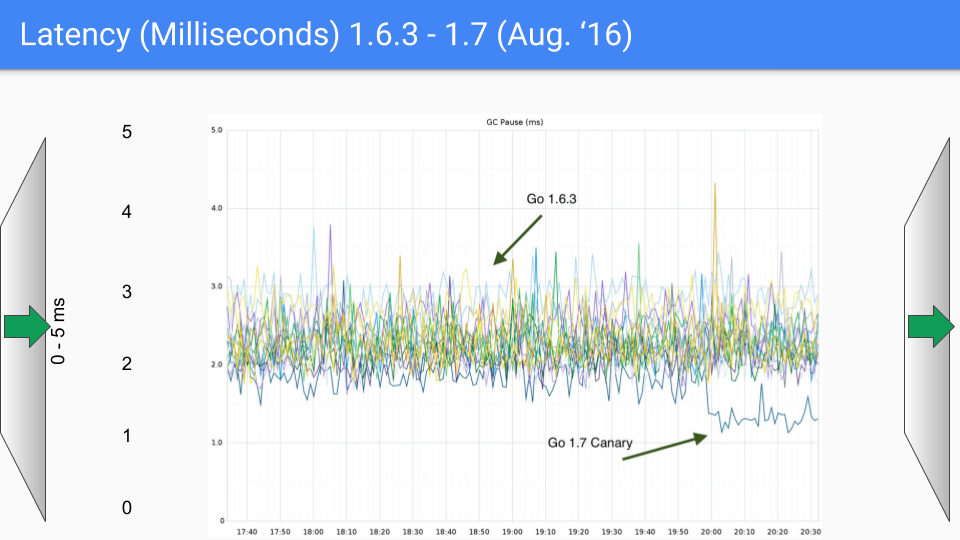
所以,你看,这是 2016 年 8 月,距离第一个版本发布一年。我们继续努力消除这些 O(heap size) 的“停止世界”过程。我们讨论的是一个 18GB 的堆。我们有更大的堆,当我们消除了这些 O(heap size) 的“停止世界”暂停时,堆的大小显然可以显著增长而不影响延迟。所以这对 1.7 版本有所帮助。
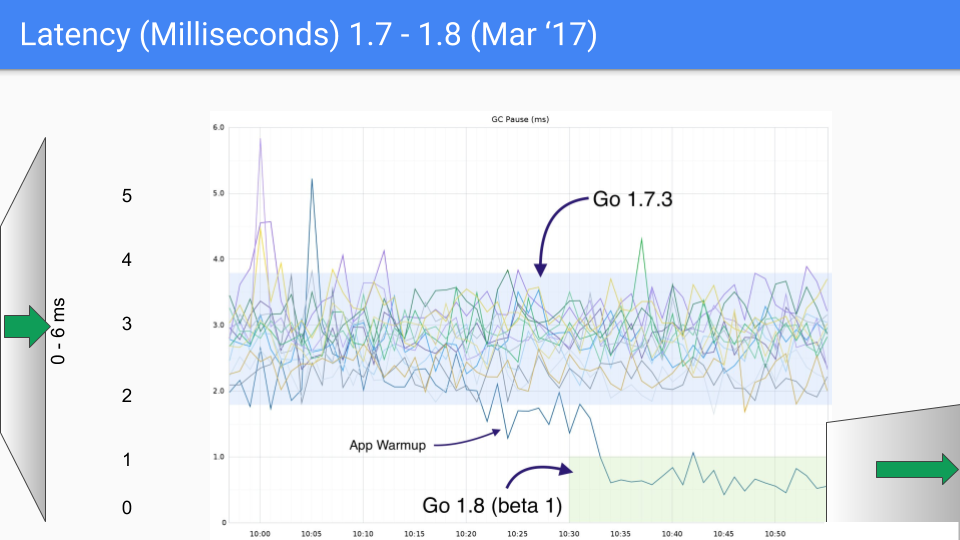
下一个版本是 2017 年 3 月。我们实现了最后一个大幅度降低延迟的改进,这得益于我们找到了如何在 GC 周期结束时避免“停止世界”栈扫描的方法。这使我们的延迟降低到亚毫秒级别。再次,Y 轴将改为 1.5 毫秒,我们看到了第三次数量级改进。
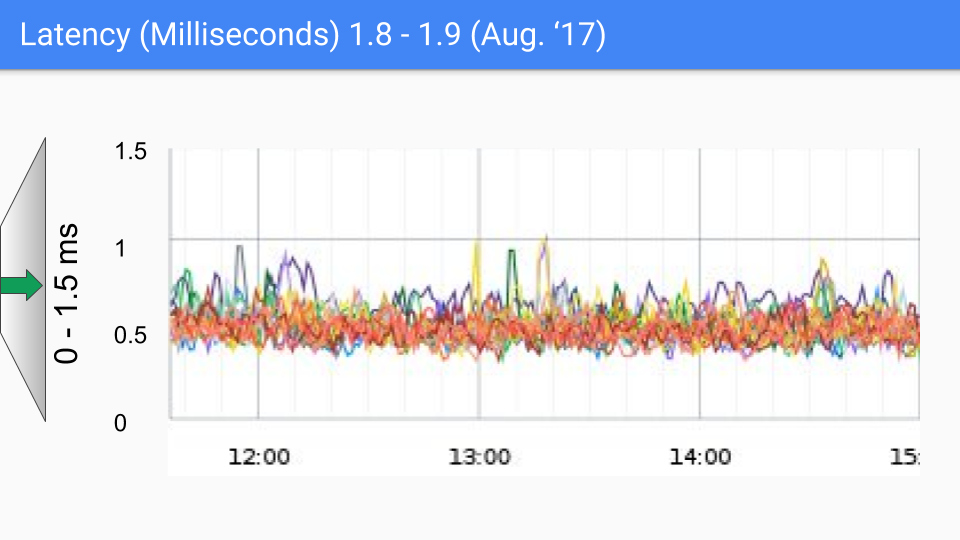
2017 年 8 月的版本改进不大。我们知道导致剩余暂停的原因。SLO 的“耳语数”(whisper number)约为 100-200 微秒,我们将朝着这个目标努力。如果您看到任何超过几百微秒的情况,我们真的很想和您谈谈,看看它是否属于我们已知的情况,或者是否是我们尚未研究过的新情况。无论如何,似乎对更低延迟的需求不大。需要注意的是,这些延迟级别可能是由各种非 GC 原因引起的,正如俗话所说:“你不必比熊跑得快,你只需要比你旁边的人跑得快。”
2018 年 2 月的 1.10 版本没有实质性变化,只是进行了一些清理和处理了边缘情况。

新的一年,新的 SLO。这是我们的 2018 年 SLO。
我们已经将 GC 周期内使用的总 CPU 降低了。
堆的大小仍然是 2 倍。
我们现在有一个目标,即每个 GC 周期“停止世界”暂停时间为 500 微秒。可能还有一点保守。
分配将继续与 GC 辅助成正比。
Pacer 已经大大改进,因此我们在稳定状态下看到了最小的 GC 辅助。
我们对此相当满意。再次强调,这不是 SLA 而是 SLO,所以这是一个目标,而不是协议,因为我们无法控制操作系统等因素。

以上是好消息。现在让我们转向并谈谈我们的失败。这些是我们的伤疤;它们有点像纹身,每个人都有。总之,它们带来更好的故事,所以让我们讲讲这些故事。

我们的第一次尝试是所谓的请求导向收集器 (ROC)。假设可以在此处看到。

那么这意味着什么?
Goroutines 是轻量级线程,看起来像 Gophers,所以这里有两个 Goroutines。它们共享一些东西,比如中间的两个蓝色对象。它们有自己的私有栈和私有对象的选择。假设左边的人想共享绿色对象。
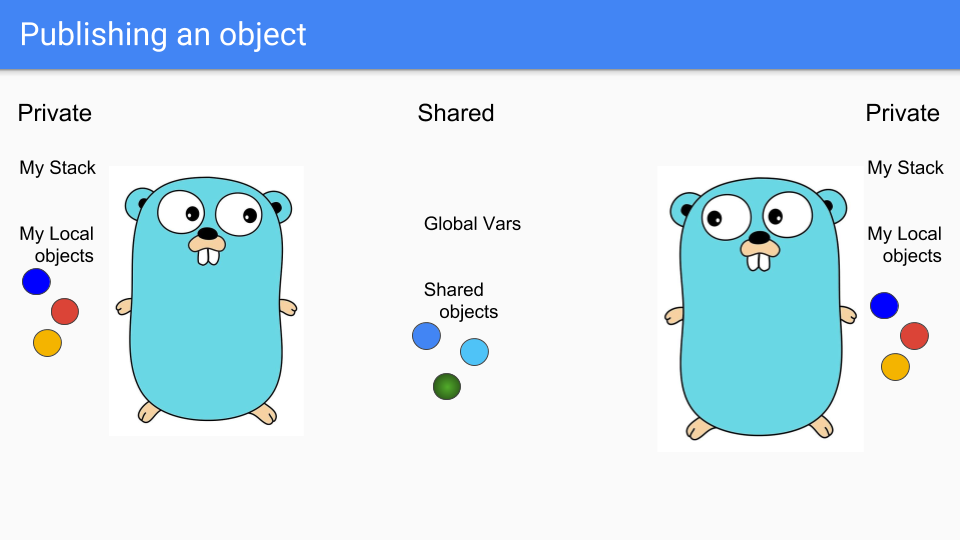
Goroutine 将其放入共享区域,以便另一个 Goroutine 可以访问它。他们可以将其挂载到共享堆中的某个对象,或者将其分配给全局变量,另一个 Goroutine 就可以看到它。

最后,左边的 Goroutine 即将消亡,可悲。
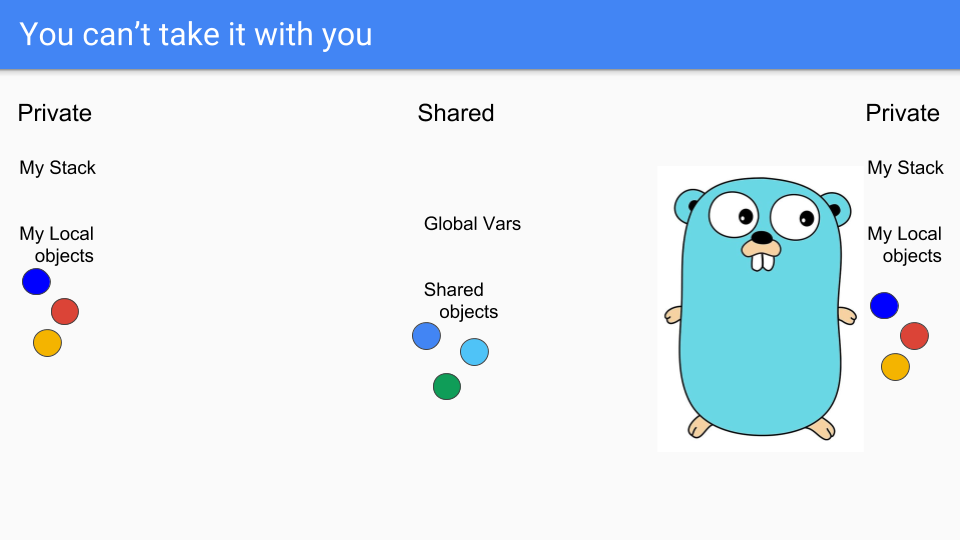
正如你所知,你不能带着你的对象一起死去。你也不能带走你的栈。栈此时实际上是空的,对象是不可达的,所以你可以简单地回收它们。

这里重要的是,所有操作都是局部的,不需要任何全局同步。这与分代 GC 等方法根本不同,希望我们从中获得的扩展性将足以让我们获胜。

这个系统还存在的另一个问题是写屏障始终处于开启状态。每当发生写入时,我们就必须查看它是否将私有对象的指针写入了公共对象。如果是,我们就必须将所指对象设为公共,然后进行可达对象的传递式遍历,确保它们也都是公共的。这是一个相当昂贵的写屏障,可能导致许多缓存未命中。
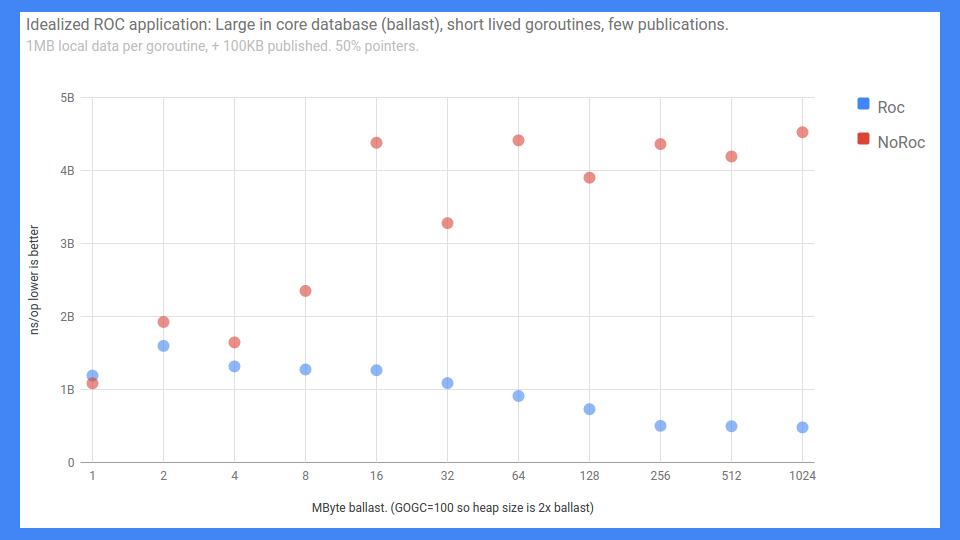
尽管如此,我们取得了一些相当不错的成功。
这是一个端到端的 RPC 基准测试。错误标记的 Y 轴从 0 到 5 毫秒(越低越好),无论如何,这就是它。X 轴基本上是负载或内存中数据库的大小。
正如你所见,如果启用 ROC 且共享不多,情况会很好地扩展。如果不启用 ROC,效果就没那么好。
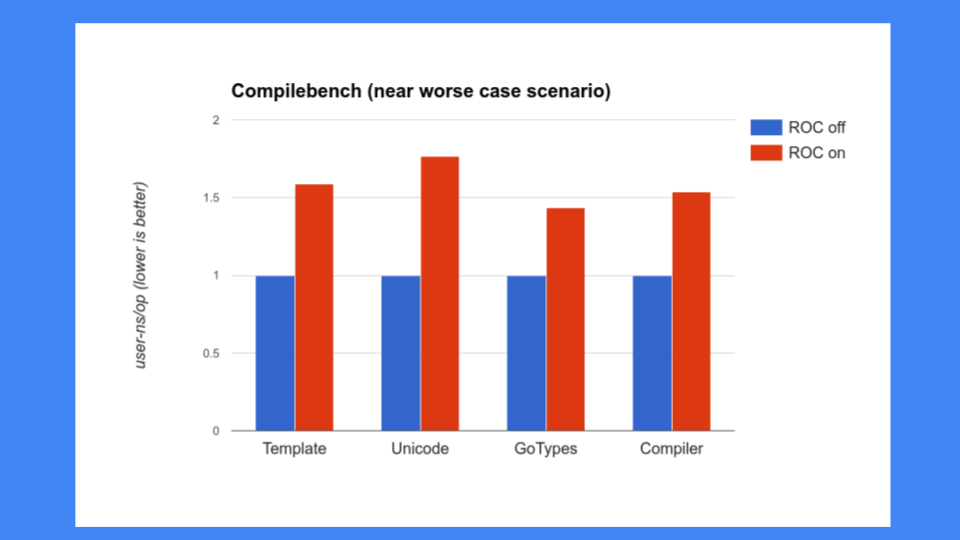
但这还不够好,我们还必须确保 ROC 不会减慢系统的其他部分。当时人们对我们的编译器非常关注,我们不能减慢编译器的速度。不幸的是,编译器恰恰是 ROC 表现不佳的程序。我们看到了 30%、40%、50% 甚至更高的性能下降,这是不可接受的。Go 以其快速的编译器而自豪,所以我们不能让编译器减慢速度,尤其是不能这么慢。
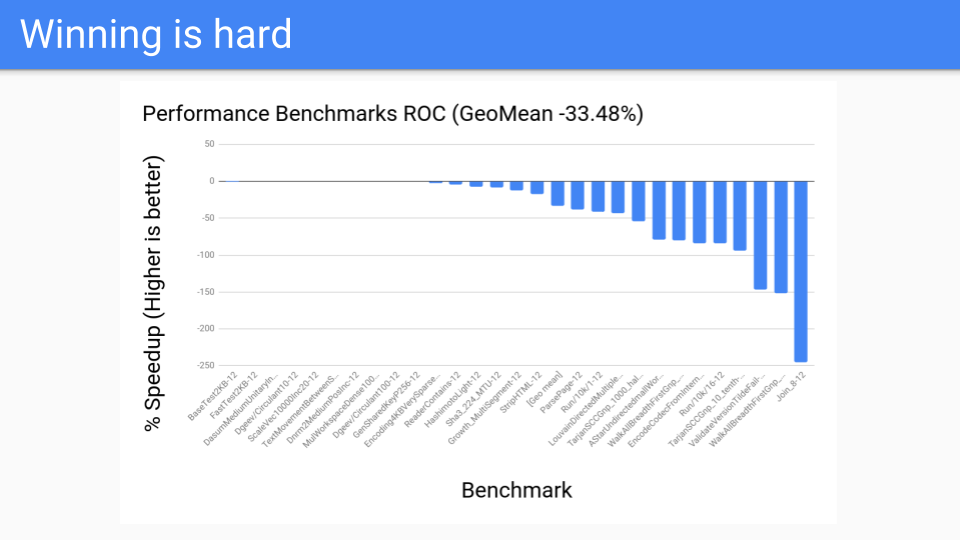
然后我们又看了一些其他程序。这些是我们的性能基准测试。我们有 200 到 300 个基准测试的语料库,这些是编译器人员决定对他们来说重要的改进。这些都不是 GC 人员选择的。结果普遍不好,ROC 不会成为赢家。

的确,我们进行了扩展,但我们只有 4 到 12 个硬件线程系统,所以我们无法克服写屏障的开销。也许将来当我们拥有 128 核系统并得到 Go 的利用时,ROC 的扩展性可能会成为优势。到那时,我们可能会重新审视,但目前 ROC 是一个失败的提议。

那么我们接下来要做什么?试试分代 GC。这是一个老套但经典的办法。ROC 行不通,所以让我们回到我们更有经验的东西上。

我们不会放弃我们的延迟,也不会放弃我们是非移动的事实。所以我们需要一个非移动的分代 GC。
那么我们能做到吗?是的,但对于分代 GC,写屏障始终开启。当 GC 周期运行时,我们使用与今天相同的写屏障,但在 GC 关闭时,我们使用一个快速的 GC 写屏障,它缓冲指针,并在缓冲区溢出时将其刷新到卡片标记表(card mark table)。
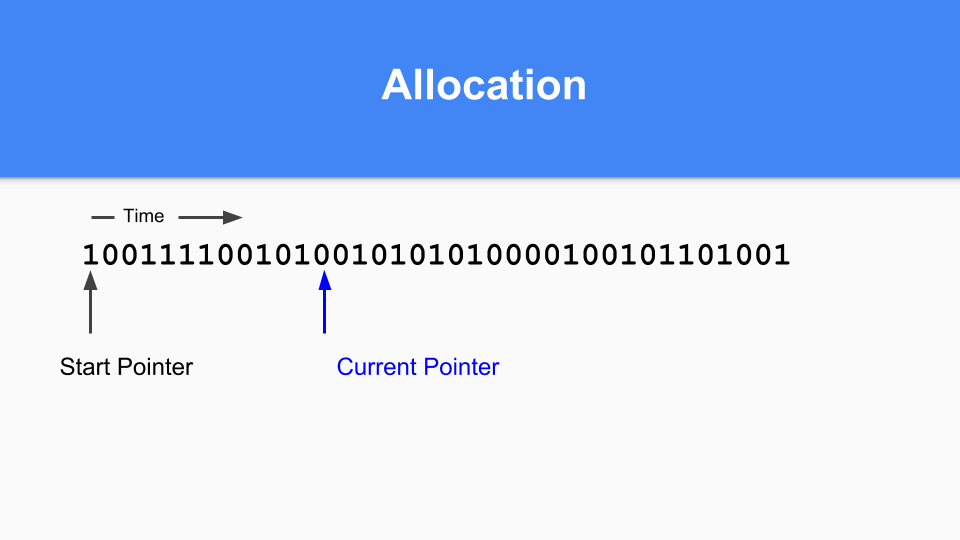
那么在非移动的情况下它将如何工作?这是标记/分配映射。基本上,您维护一个当前指针。当您进行分配时,您会寻找下一个零,找到零后,您就在该空间中分配一个对象。
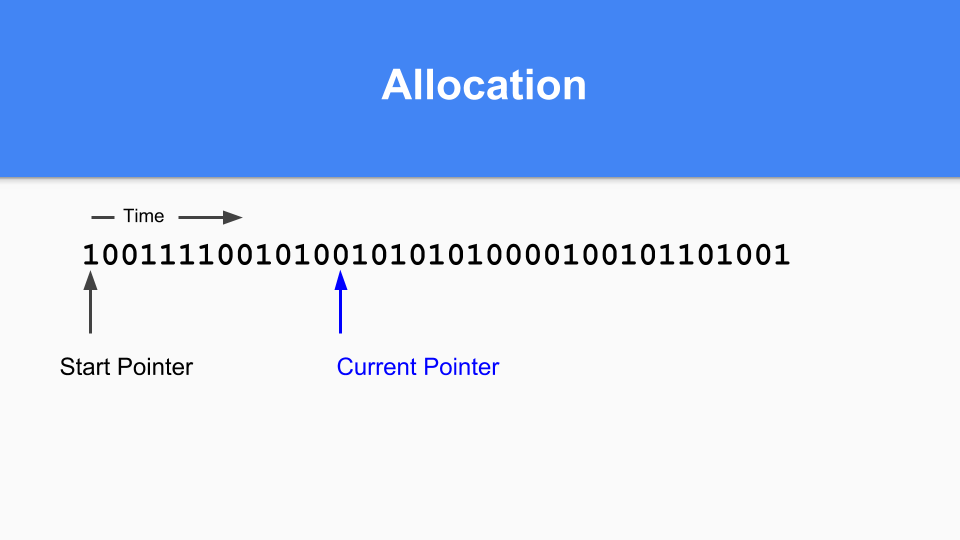
然后更新当前指针指向下一个零。
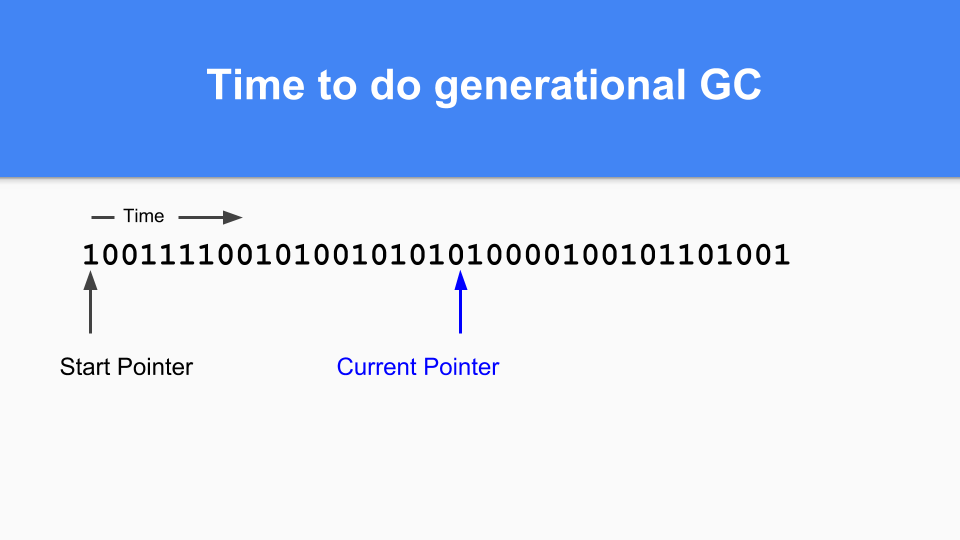
继续进行,直到某个时候是时候进行代际 GC 了。您会注意到,如果标记/分配向量中有 1,则该对象在上次 GC 时是活动的,因此它是成熟的。如果它是零并且您访问到它,那么您就知道它是年轻的。
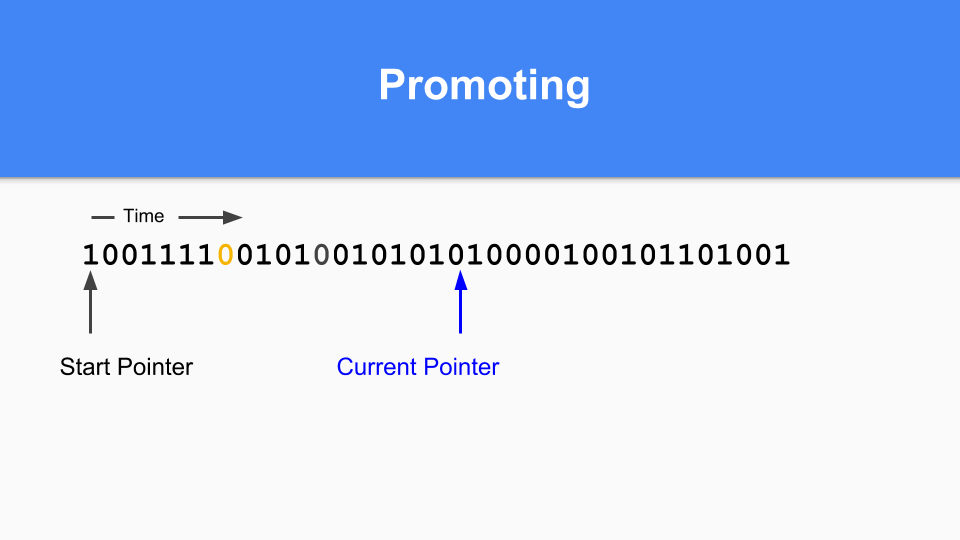
那么如何进行提升(promoting)呢?如果您发现标记为 1 的对象指向标记为 0 的对象,那么您只需将该零更改为 1 来提升被指向的对象。
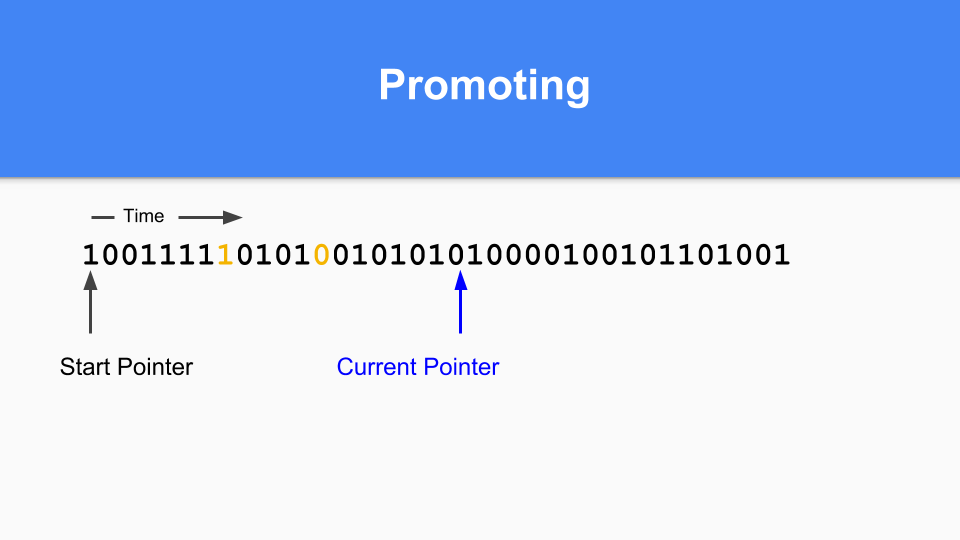
您必须进行传递式遍历以确保所有可达对象都被提升。
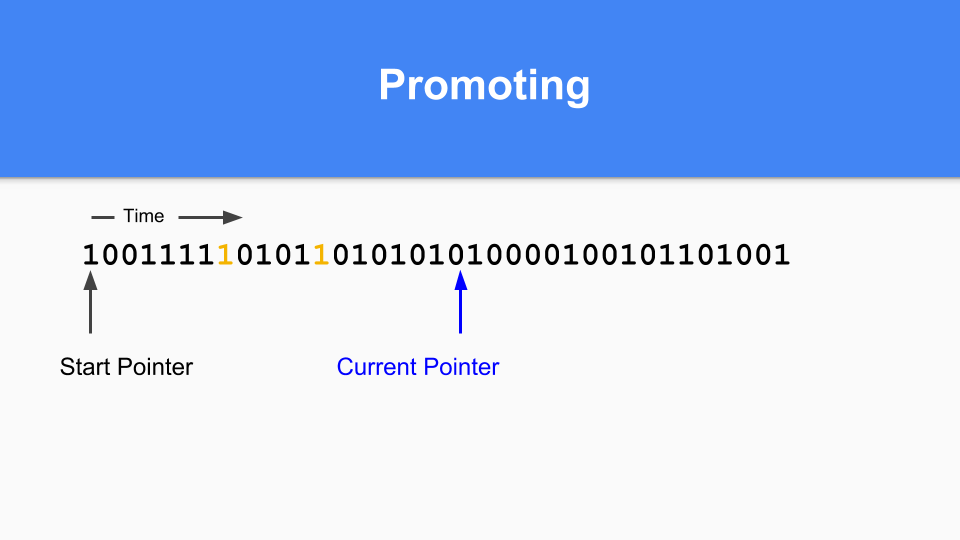
当所有可达对象都被提升后,次要 GC 终止。

最后,要完成您的分代 GC 周期,只需将当前指针重置回向量的开头,然后继续。所有未被该 GC 周期访问的零都将被释放并可重用。正如你们中的许多人所知,这被称为“粘性位”(sticky bits),是由 Hans Boehm 和他的同事发明的。
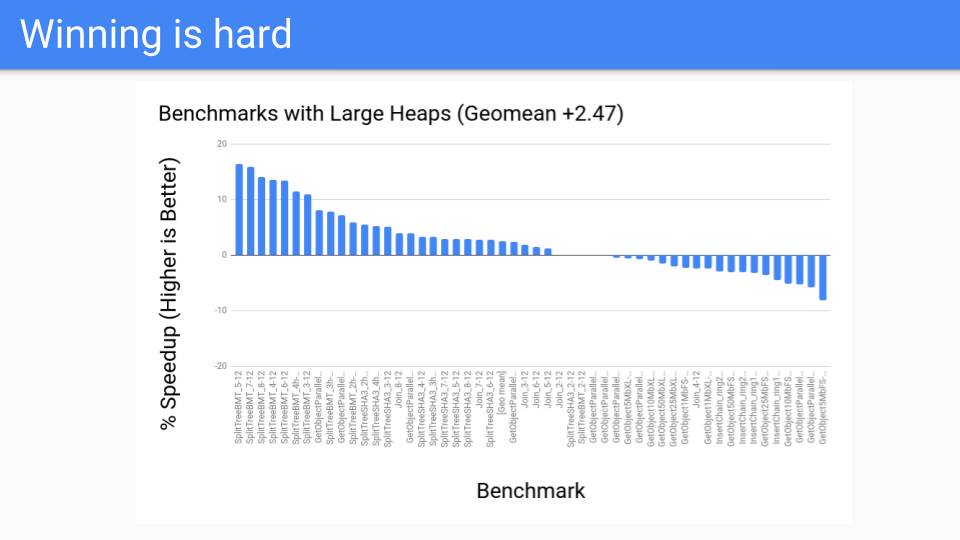
那么性能如何?对于大堆来说还不错。这些是 GC 应该表现良好的基准测试。这一切都很好。
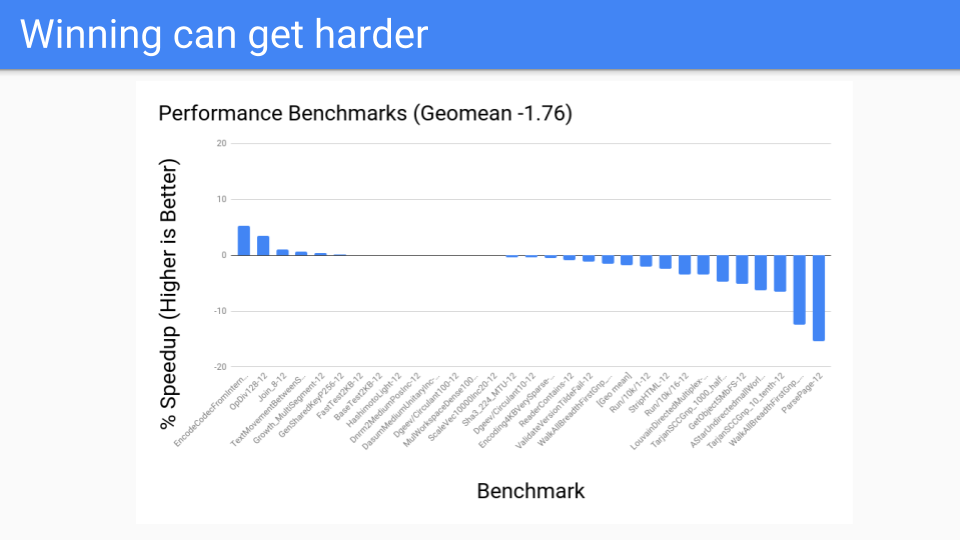
然后我们在性能基准测试上进行了测试,结果并不理想。那么发生了什么?

写屏障是快速的,但仍然不够快。而且很难对其进行优化。例如,如果对象分配和下一个安全点之间有初始化写入,就可以进行写屏障的省略。但我们必须转向一个系统,在这个系统中,每个指令都有一个 GC 安全点,所以将来没有任何写屏障可以被省略。

我们还有逃逸分析(escape analysis),它越来越好。还记得我们谈到的面向值的东西吗?我们传递实际值而不是函数指针。由于我们传递的是值,逃逸分析只需要进行过程内逃逸分析(intraprocedural escape analysis),而不是过程间逃逸分析(interprocedural analysis)。
当然,在局部对象指针逃逸的情况下,对象将被分配到堆上。
并不是说分代假设对 Go 不成立,只是年轻的对象在栈上存活和死亡。结果是,分代收集的效果不如在其他托管运行时语言中看到的。

因此,这些针对写屏障的阻力开始聚集。今天,我们的编译器比 2014 年好得多。逃逸分析捕获了许多对象并将它们放在栈上——这些对象是分代收集器本可以提供帮助的对象。我们开始创建工具来帮助用户查找逃逸的对象,如果只是小问题,他们可以修改代码并帮助编译器在栈上进行分配。
用户越来越聪明地拥抱面向值的方法,指针数量正在减少。数组和映射存储值而不是指向结构体的指针。一切都很好。
但这并不是写屏障在 Go 中面临长期挑战的主要令人信服的原因。
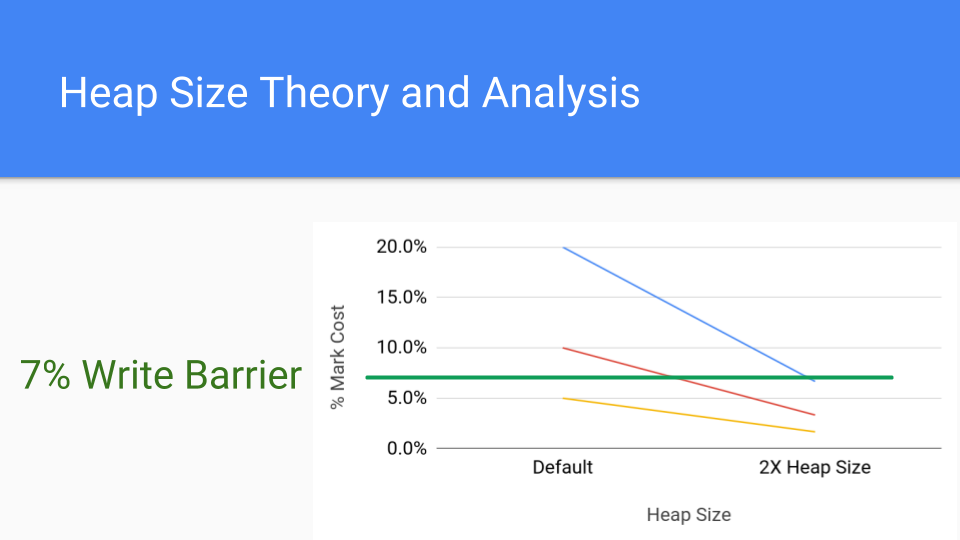
让我们看看这张图。这是一张标记成本的分析图。每条线代表一种可能的标记成本不同的应用程序。假设您的标记成本为 20%,这相当高,但有可能。红线是 10%,仍然很高。较低的线是 5%,这大约是目前写屏障的成本。那么,如果将堆大小加倍会怎样?那就是右边的点。标记阶段的累积成本会大大降低,因为 GC 周期不那么频繁了。写屏障成本是恒定的,所以增加堆大小的成本将使标记成本低于写屏障的成本。
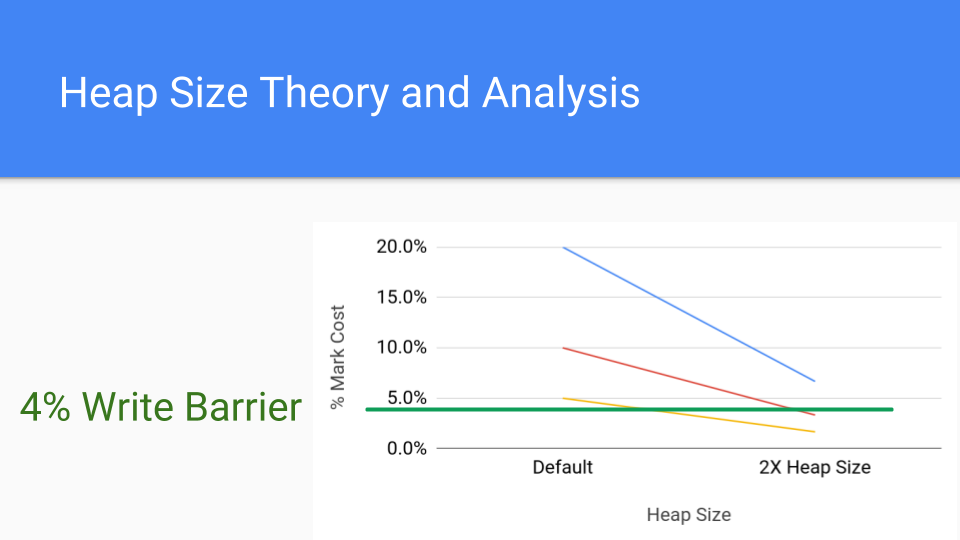
这里是写屏障更常见的成本,即 4%,我们看到即使有了这个成本,通过简单地增加堆大小,也可以将标记屏障的成本降低到写屏障成本之下。
分代 GC 的真正价值在于,在查看 GC 时间时,写屏障的成本被忽略了,因为它们被分散到变异器中。这是分代 GC 的主要优势,它大大减少了完整 GC 周期的长时间 STW 时间,但并不一定能提高吞吐量。Go 没有这个问题,所以它必须更仔细地关注吞吐量问题,而这正是我们所做的。

这有很多失败,失败带来了食物和午餐。我正在进行我一贯的抱怨:“如果不是写屏障,这该多好啊。”
与此同时,Austin 刚刚花了一个小时与谷歌的一些硬件 GC 人员交谈,他建议我们与他们联系,看看如何获得硬件 GC 支持可能会有帮助。然后我开始讲起零填充缓存行、可重启原子序列等零碎故事,这些在我为一家大型硬件公司工作时并没有奏效。我们确实在名为 Itanium 的芯片中实现了一些东西,但我们无法将其应用到如今更受欢迎的芯片中。所以这个故事的寓意很简单:利用我们拥有的硬件。
总之,这让我们开始讨论,有没有什么疯狂的想法?

不用写屏障的卡片标记(card marking)怎么样?事实证明,Austin 有这些文件,他把所有疯狂的想法都写在这些文件里,但不知何故他没有告诉我。我猜这是一种治疗方式。我以前和 Eliot 也是这样。新想法很容易被摧毁,需要保护它们并使其更强大,然后再让它们走向世界。不过,他提出了这个想法。
这个想法是,您在每个卡片中维护一个成熟指针的哈希。如果将指针写入卡片,哈希值将发生变化,卡片将被视为已标记。这将用哈希的成本来替代写屏障的成本。

但更重要的是,它与硬件兼容。
今天的现代架构拥有 AES(高级加密标准)指令。其中一条指令可以执行加密级别的哈希,通过加密级别的哈希,如果我们遵循标准的加密策略,就不必担心哈希冲突。所以哈希不会花费我们太多成本,但我们必须加载我们要哈希的内容。幸运的是,我们是顺序遍历内存,所以我们获得了非常好的内存和缓存性能。如果您有一个 DIMM 并且访问顺序地址,那么这就是一个胜利,因为它们比访问随机地址更快。硬件预取器也会启动,这也会有所帮助。总之,我们有 50 年、60 年设计硬件来运行 Fortran、C 和 SPECint 基准测试的经验。硬件能快速运行这类东西也就不足为奇了。
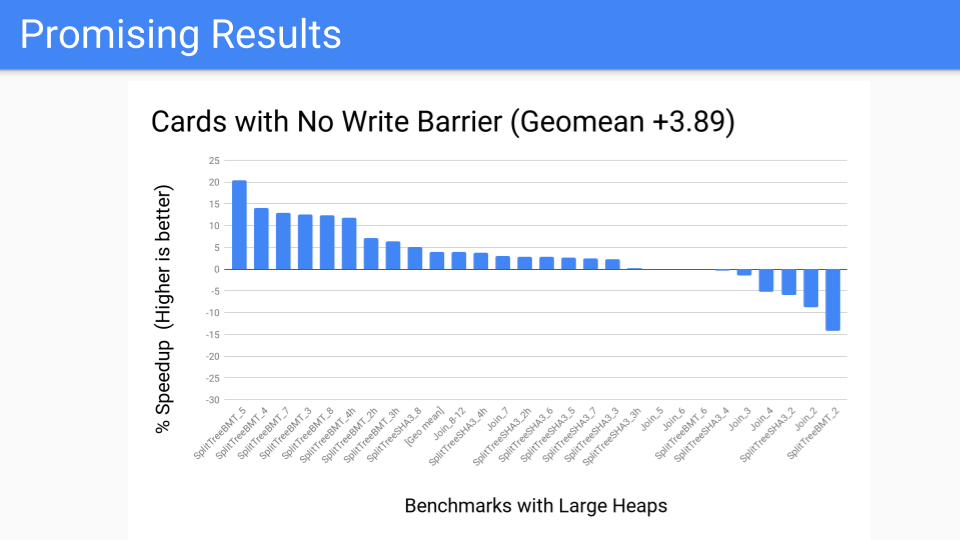
我们进行了测量。这相当不错。这是大堆的基准测试套件,应该表现良好。
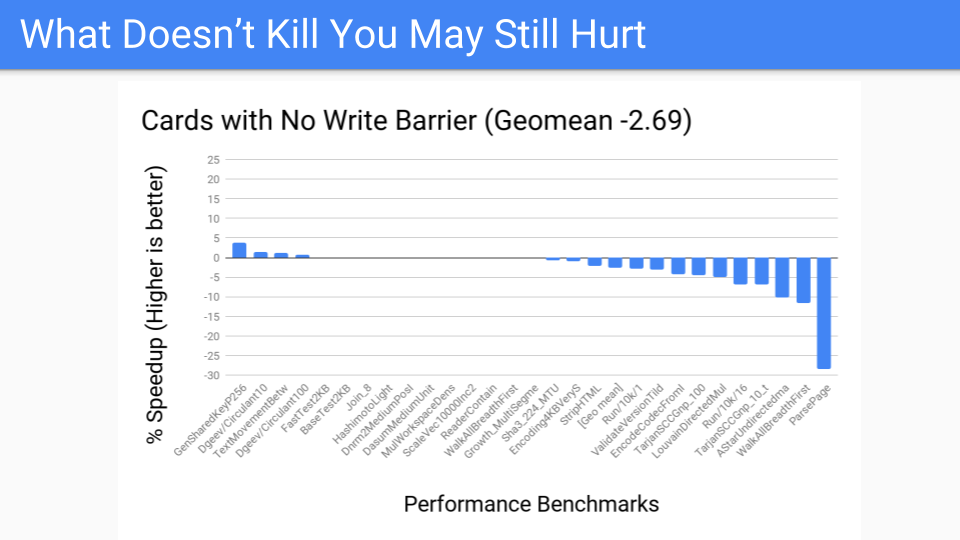
然后我们问,性能基准测试看起来怎么样?不太好,有几个异常值。但现在我们已经将写屏障从始终在变异器中开启,转移到作为 GC 周期的一部分运行。现在,关于是否进行分代 GC 的决定将被推迟到 GC 周期开始。我们有更多的控制权,因为我们已经将卡片工作本地化了。既然我们有了工具,就可以将其交给 Pacer,它可以很好地动态地关闭那些落在右侧(不适合分代 GC)的程序。但这会赢吗?我们必须知道,或者至少思考一下硬件未来的样子。

未来的内存是什么样的?
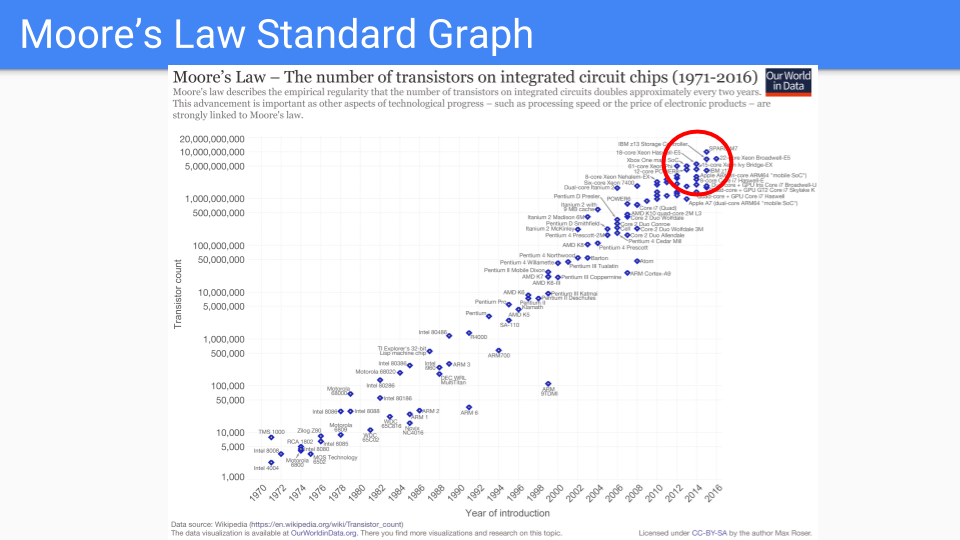
让我们看看这张图。这是经典的摩尔定律图。Y 轴是芯片上的晶体管数量(对数尺度)。X 轴是 1971 年到 2016 年的年份。我注意到,这些年份是有人预测摩尔定律已死的年份。
Dennard 缩放定律大约十年前就结束了频率改进。新工艺的爬坡时间更长。所以,从 2 年变成 4 年或更长。因此,很明显我们正在进入摩尔定律放缓的时代。
让我们只看红色圆圈中的芯片。这些是他们在维持摩尔定律方面表现最好的芯片。
这些芯片的逻辑越来越简单,并且被大量复制。大量的相同核心、多个内存控制器和缓存、GPU、TPU 等。
随着我们不断简化和增加复制,我们渐近地会得到几根导线、一个晶体管和一个电容器。换句话说,就是 DRAM 内存单元。
换句话说,我们认为增加一倍内存的价值将大于增加一倍核心。
原始图表 来源:www.kurzweilai.net/ask-ray-the-future-of-moores-law。
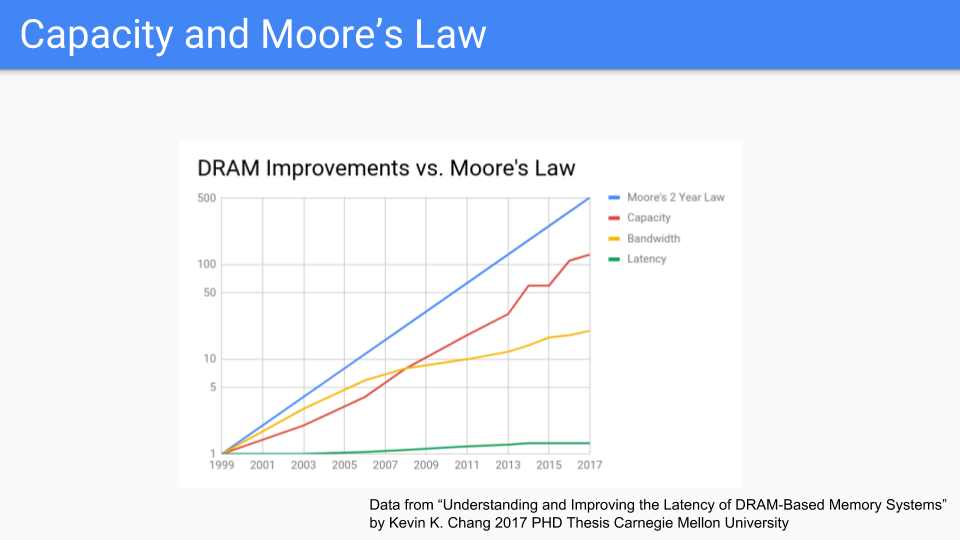
让我们看看另一张专注于 DRAM 的图。这些是来自卡内基梅隆大学近期博士论文的数据。如果我们看这张图,我们会看到摩尔定律是蓝线。红线是容量,它似乎遵循摩尔定律。奇怪的是,我看到一张图表,可以追溯到 1939 年我们还在使用鼓式存储器,那时容量和摩尔定律就一直在同步前进,所以这张图已经持续了很长时间,肯定比在场的大多数人都要长。
如果我们比较这张图与 CPU 频率或各种“摩尔定律已死”的图表,我们会得出结论,内存,或者至少是芯片容量,将比 CPU 更长地遵循摩尔定律。带宽(黄线)不仅与内存频率有关,还与芯片引脚数量有关,所以它跟不上那么好,但也不算太差。
延迟(绿线)表现非常差,尽管我注意到顺序访问的延迟比随机访问的延迟要好。
(数据来自“理解和改进 DRAM 内存系统的延迟”,部分满足获得电气与计算机工程博士学位的要求,Kevin K. Chang M.S.,电气与计算机工程,卡内基梅隆大学 B.S.,电气与计算机工程,卡内基梅隆大学,卡内基梅隆大学,匹兹堡,PA,2017 年 5 月”。参见 Kevin K. Chang 的论文。 介绍中的原始图表不是我能轻易绘制摩尔定律线的那种形式,所以我更改了 X 轴使其更均匀。)
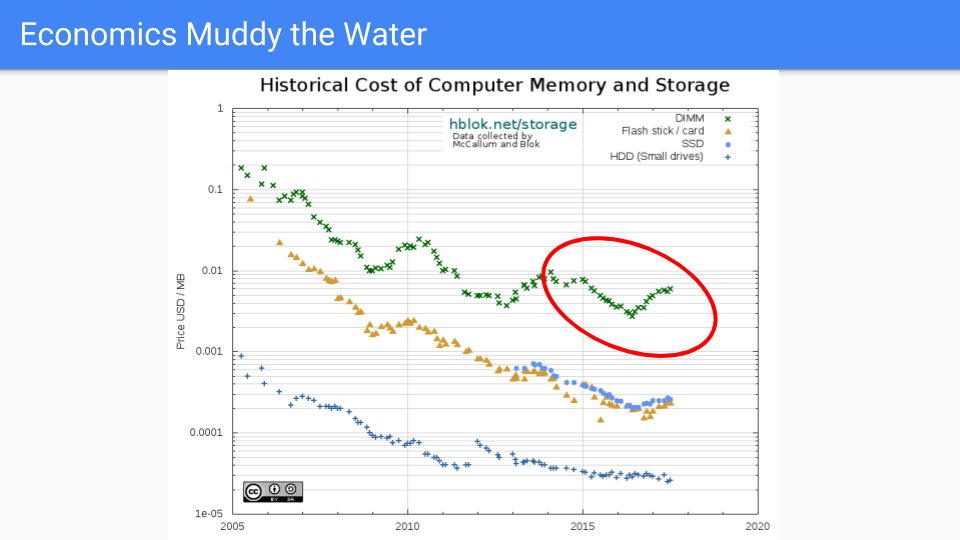
让我们看看实际的 DRAM 定价。从 2005 年到 2016 年,价格普遍下降。我选择 2005 年是因为大约在那时 Dennard 缩放定律结束,频率改进也随之结束。
如果您看看红色圆圈,也就是我们致力于降低 Go GC 延迟的时间,我们会看到在前几年价格表现不错。最近,情况不太好,因为需求超过了供应,导致过去两年价格上涨。当然,晶体管没有变大,在某些情况下芯片容量仍在增加,所以这是市场力量驱动的。RAMBUS 和其他芯片制造商表示,到 2019-2020 年,我们将看到下一个工艺收缩。
我将避免推测内存行业的全球市场力量,只是指出价格是周期性的,从长远来看,供应倾向于满足需求。
从长远来看,我们相信内存价格的下降速度将远快于 CPU 价格。
(来源 https://hblok.net/blog/ 和 https://hblok.net/storage_data/storage_memory_prices_2005-2017-12.png)
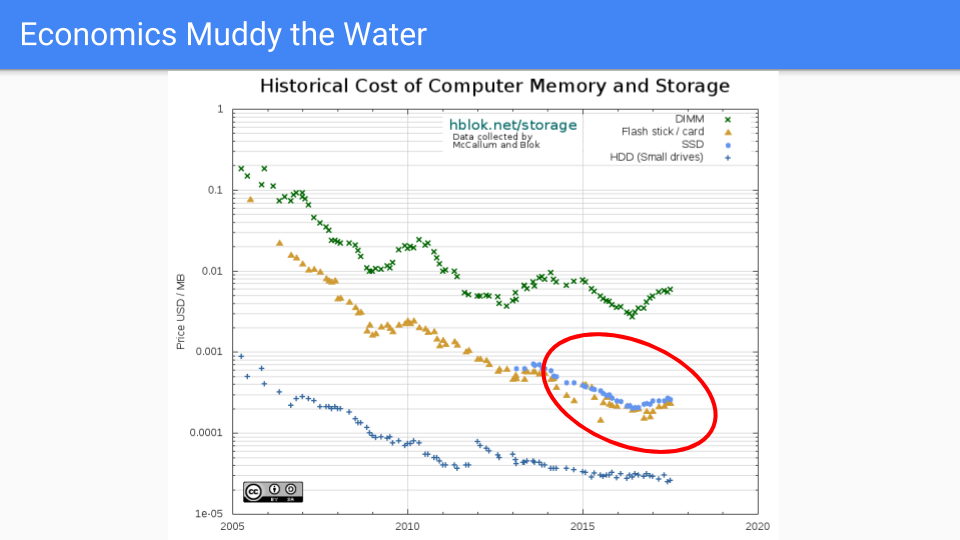
让我们看看这条线。嗯,如果我们能在这条线上就好了。这是 SSD 线。它在保持价格低廉方面做得更好。这些芯片的材料物理学比 DRAM 更复杂。逻辑更复杂,每个单元有半打左右的晶体管,而不是一个。
未来,DRAM 和 SSD 之间将有一条线,NVRAM(如英特尔的 3D XPoint 和相变内存 PCM)将位于其中。在未来十年,此类内存的可用性增加可能会变得更加主流,这将进一步加强增加内存是为我们的服务器增加价值的廉价方式这一理念。
更重要的是,我们可以期待看到其他与 DRAM 竞争的替代品。我不敢说五到十年后哪种会占优,但竞争将非常激烈,堆内存将朝着我们在这里突出显示的蓝色 SSD 线方向发展。
所有这些都强化了我们避免始终开启的屏障而选择增加内存的决定。

那么,这一切对 Go 的未来意味着什么?

我们打算让运行时更加灵活和健壮,同时关注用户反馈的边缘情况。希望能够收紧调度器,获得更好的确定性和公平性,但我们不想牺牲任何性能。
我们也不打算增加 GC API 的表面积。我们已经有近十年的时间了,我们有两个“旋钮”,这感觉差不多。没有一个应用程序值得我们添加新的标志。
我们还将研究如何改进我们已经相当不错的逃逸分析,并针对 Go 的面向值编程进行优化。不仅在编程方面,还在我们为用户提供的工具方面。
在算法上,我们将专注于那些能够最小化屏障使用(尤其是那些始终开启的屏障)的设计空间。
最后,也是最重要的,我们希望在未来 5 年,甚至可能 10 年里,能够利用摩尔定律倾向于 RAM 而非 CPU 的趋势。
就这样。谢谢。

附注:Go 团队正在招聘工程师,协助开发和维护 Go 运行时和编译器工具链。
感兴趣吗?请查看我们的 空缺职位。
下一篇文章:使用 Go Cloud 进行可移植的云编程
上一篇文章:更新 Go 行为准则
博客索引