Go 博客
Go 切片:用法和内部原理
引言
Go 的切片类型提供了一种方便高效的方式来处理类型化数据序列。切片类似于其他语言中的数组,但具有一些不寻常的特性。本文将探讨切片是什么以及如何使用它们。
数组
切片类型是构建在 Go 数组类型之上的抽象,因此要理解切片,我们必须先理解数组。
数组类型定义指定了长度和元素类型。例如,类型 [4]int 表示一个包含四个整数的数组。数组的大小是固定的;其长度是类型的一部分([4]int 和 [5]int 是不同的、不兼容的类型)。数组可以像往常一样进行索引,因此表达式 s[n] 访问第 n 个元素,从零开始计数。
var a [4]int
a[0] = 1
i := a[0]
// i == 1
数组不需要显式初始化;数组的零值是一个可以直接使用的数组,其元素本身也已归零。
// a[2] == 0, the zero value of the int type
[4]int 在内存中的表示就是四个整数值按顺序排列。

Go 的数组是值类型。数组变量表示整个数组;它不是指向数组第一个元素的指针(如 C 语言中的情况)。这意味着当你赋值或传递数组值时,会复制其内容。(要避免复制,你可以传递一个数组的指针,但那样它就是数组的指针,而不是数组本身。)思考数组的一种方式是将其视为一种结构体,但拥有索引字段而不是命名字段:一个固定大小的复合值。
数组字面量可以这样指定
b := [2]string{"Penn", "Teller"}
或者,你可以让编译器为你计算数组元素数量
b := [...]string{"Penn", "Teller"}
在这两种情况下,b 的类型都是 [2]string。
切片
数组有其用武之地,但它们有点不够灵活,所以在 Go 代码中你很少看到它们。然而,切片则无处不在。它们建立在数组之上,提供了强大的功能和便利性。
切片的类型规范是 []T,其中 T 是切片中元素的类型。与数组类型不同,切片类型没有指定长度。
切片字面量的声明方式与数组字面量相同,只是省略了元素计数
letters := []string{"a", "b", "c", "d"}
可以使用内置函数 make 来创建切片,该函数的签名如下:
func make([]T, len, cap) []T
其中 T 代表要创建的切片的元素类型。make 函数接受一个类型、一个长度和一个可选的容量。调用时,make 会分配一个数组并返回一个引用该数组的切片。
var s []byte
s = make([]byte, 5, 5)
// s == []byte{0, 0, 0, 0, 0}
当省略容量参数时,它默认为指定的长度。以下是相同代码的更简洁版本
s := make([]byte, 5)
可以使用内置的 len 和 cap 函数来检查切片的长度和容量。
len(s) == 5
cap(s) == 5
接下来的两个部分将讨论长度和容量之间的关系。
切片的零值是 nil。对于 nil 切片,len 和 cap 函数都将返回 0。
还可以通过“切片”现有切片或数组来形成切片。切片是通过指定一个半开区间来实现的,其中有两个用冒号分隔的索引。例如,表达式 b[1:4] 创建一个包含 b 中从索引 1 到 3 的元素的切片(结果切片的索引将是 0 到 2)。
b := []byte{'g', 'o', 'l', 'a', 'n', 'g'}
// b[1:4] == []byte{'o', 'l', 'a'}, sharing the same storage as b
切片表达式的开始和结束索引是可选的;它们分别默认为零和切片的长度。
// b[:2] == []byte{'g', 'o'}
// b[2:] == []byte{'l', 'a', 'n', 'g'}
// b[:] == b
这也是通过数组创建切片的语法
x := [3]string{"Лайка", "Белка", "Стрелка"}
s := x[:] // a slice referencing the storage of x
切片内部机制
切片是数组段的描述符。它由指向数组的指针、段的长度以及其容量(段的最大长度)组成。

我们之前通过 make([]byte, 5) 创建的变量 s 的结构如下:
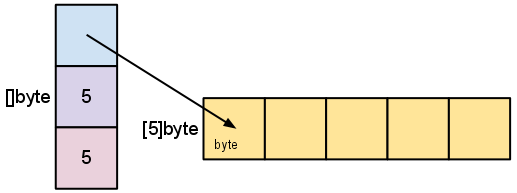
长度是切片引用的元素数量。容量是底层数组中元素的数量(从切片指针指向的元素开始)。长度和容量之间的区别将在我们遍历接下来的几个示例时变得清楚。
当我们切片 s 时,观察切片数据结构的变化以及它们与底层数组的关系
s = s[2:4]
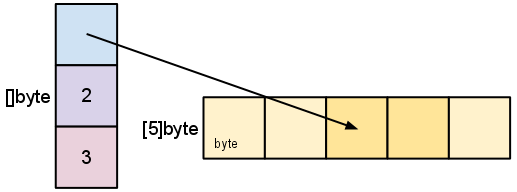
切片不会复制切片的数据。它创建一个指向原始数组的新切片值。这使得切片操作与操作数组索引一样高效。因此,修改重新切片的元素(而不是切片本身)会修改原始切片的元素。
d := []byte{'r', 'o', 'a', 'd'}
e := d[2:]
// e == []byte{'a', 'd'}
e[1] = 'm'
// e == []byte{'a', 'm'}
// d == []byte{'r', 'o', 'a', 'm'}
前面我们切片了 s,使其长度小于其容量。我们可以通过再次切片来将 s 扩展到其容量。
s = s[:cap(s)]
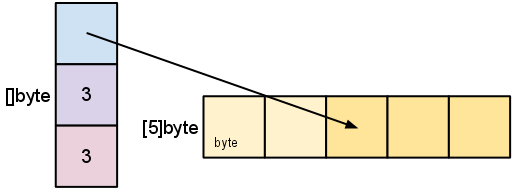
切片不能扩展到超出其容量。尝试这样做会导致运行时恐慌,就像索引超出切片或数组边界时一样。同样,切片也不能重新切片到零以下以访问数组中较早的元素。
扩展切片(复制和附加函数)
要增加切片的容量,必须创建一个新的、更大的切片,并将原始切片的内容复制到其中。这种技术是其他语言中动态数组实现幕后工作的方式。下一个示例通过创建一个新切片 t,将 s 的内容复制到 t,然后将切片值 t 赋给 s 来将 s 的容量翻倍。
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
for i := range s {
t[i] = s[i]
}
s = t
这个常见操作的循环部分通过内置的 copy 函数变得更容易。顾名思义,copy 将数据从源切片复制到目标切片。它返回复制的元素数量。
func copy(dst, src []T) int
copy 函数支持不同长度切片之间的复制(它只复制到较少元素数量的范围内)。此外,copy 可以处理源切片和目标切片共享同一个底层数组的情况,并正确处理重叠切片。
使用 copy,我们可以简化上面的代码片段。
t := make([]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
一个常见的操作是向切片末尾添加数据。此函数将字节元素附加到字节切片,并在需要时增长切片,然后返回更新后的切片值。
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
可以使用 AppendByte 如下:
p := []byte{2, 3, 5}
p = AppendByte(p, 7, 11, 13)
// p == []byte{2, 3, 5, 7, 11, 13}
像 AppendByte 这样的函数很有用,因为它们提供了对切片如何增长的完全控制。根据程序的特性,可能希望以更小或更大的块分配,或者对重新分配的大小设置上限。
但是大多数程序不需要完全控制,所以 Go 提供了一个内置的 append 函数,它适用于大多数情况;它的签名如下:
func append(s []T, x ...T) []T
append 函数将元素 x 附加到切片 s 的末尾,并在需要更大的容量时增长切片。
a := make([]int, 1)
// a == []int{0}
a = append(a, 1, 2, 3)
// a == []int{0, 1, 2, 3}
要将一个切片附加到另一个切片,请使用 ... 将第二个参数展开为参数列表。
a := []string{"John", "Paul"}
b := []string{"George", "Ringo", "Pete"}
a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])"
// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
由于切片的零值(nil)表现得像一个零长度切片,你可以声明一个切片变量,然后在循环中向其追加元素。
// Filter returns a new slice holding only
// the elements of s that satisfy fn()
func Filter(s []int, fn func(int) bool) []int {
var p []int // == nil
for _, v := range s {
if fn(v) {
p = append(p, v)
}
}
return p
}
一个可能的“陷阱”
如前所述,重新切片切片不会复制底层数组。整个数组将一直保留在内存中,直到不再被引用。有时这会导致程序在只需要一小部分数据时仍然占用所有数据在内存中。
例如,这个 FindDigits 函数将一个文件加载到内存中,并查找第一组连续的数字,将它们作为新的切片返回。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
这段代码的行为符合预期,但返回的 []byte 指向一个包含整个文件的数组。由于切片引用原始数组,只要切片保留在那里,垃圾回收器就无法释放数组;文件中的少量有用字节会将整个内容保留在内存中。
为了解决这个问题,可以在返回之前将相关数据复制到一个新的切片中。
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
可以使用 append 来构建此函数的一个更简洁的版本。留给读者作为练习。