Go 博客
gopls 扩展以应对不断增长的 Go 生态系统
今年夏初,Go 团队发布了 v0.12 版本的 gopls,这是 Go 的 语言服务器,其核心重写使其能够扩展到更大的代码库。这是我们一年努力的成果,我们很高兴能分享我们的进展,并略谈新的架构及其对 gopls 未来意味着什么。
自 v0.12 发布以来,我们对新设计进行了微调,重点是使交互式查询(如自动补全或查找引用)的速度与 v0.11 一样快,尽管内存中存储的状态要少得多。如果您还没有尝试过,我们希望您会试用一下。
$ go install golang.org/x/tools/gopls@latest
我们非常希望通过这次 简短调查 了解您的使用体验。
内存使用量和启动时间降低
在深入细节之前,让我们先看看结果!下图显示了 GitHub 上 28 个最受欢迎的 Go 存储库的启动时间和内存使用量的变化。这些测量是在打开随机选择的 Go 文件并等待 gopls 完全加载其状态后进行的,并且由于我们假设初始索引会在多次编辑会话中分摊,因此我们是在第二次打开文件时进行这些测量的。

在这些存储库中,平均节省量约为 75%,但内存减少是非线性的:随着项目变大,内存使用的相对降低幅度也随之增加。我们将在下面详细解释这一点。
Gopls 与不断发展的 Go 生态系统
Gopls 为与语言无关的编辑器提供了类似 IDE 的功能,例如自动补全、格式化、交叉引用和重构。自 2018 年诞生以来,gopls 整合了许多分散的命令行工具,如 guru、gorename 和 goimports,并已成为 VS Code Go 扩展以及许多其他编辑器和 LSP 插件的默认后端。也许您一直在通过编辑器使用 gopls 而未曾知晓——这就是我们的目标!
五年前,gopls 通过维护有状态会话即可提高性能。而旧的命令行工具每次执行都必须从头开始,gopls 可以保存中间结果以显著降低延迟。但所有这些状态都有代价,随着时间的推移,我们越来越多地 从用户那里听到 gopls 高内存使用量几乎令人无法忍受。
与此同时,Go 生态系统不断发展,大型存储库中的代码量也在增加。 Go 工作区允许开发人员同时处理多个模块,而 容器化开发将语言服务器置于资源日益受限的环境中。代码库越来越大,开发环境越来越小。我们需要改变 gopls 扩展的方式以跟上步伐。
重新审视 gopls 的编译器起源
在许多方面,gopls 类似于编译器:它需要读取、解析、类型检查和分析 Go 源文件,为此它使用了 Go 标准库和 golang.org/x/tools 模块提供的许多编译器 构建块。这些构建块使用了“符号编程”技术:在运行的编译器中,有一个单一的对象或“符号”代表每个函数,例如 fmt.Println。任何对函数的引用都表示为指向其符号的指针。要测试两个引用是否指代同一符号,您无需考虑名称。只需比较指针。指针比字符串小得多,指针比较也非常便宜,因此符号是表示程序等复杂结构的有效方式。
为了快速响应请求,gopls v0.11 将所有这些符号保存在内存中,就好像 gopls 在“一次编译您的整个程序”一样。结果是内存占用与正在编辑的源代码成比例且大得多(例如,类型化的语法树通常比源代码文本大 30 倍!)。
独立编译
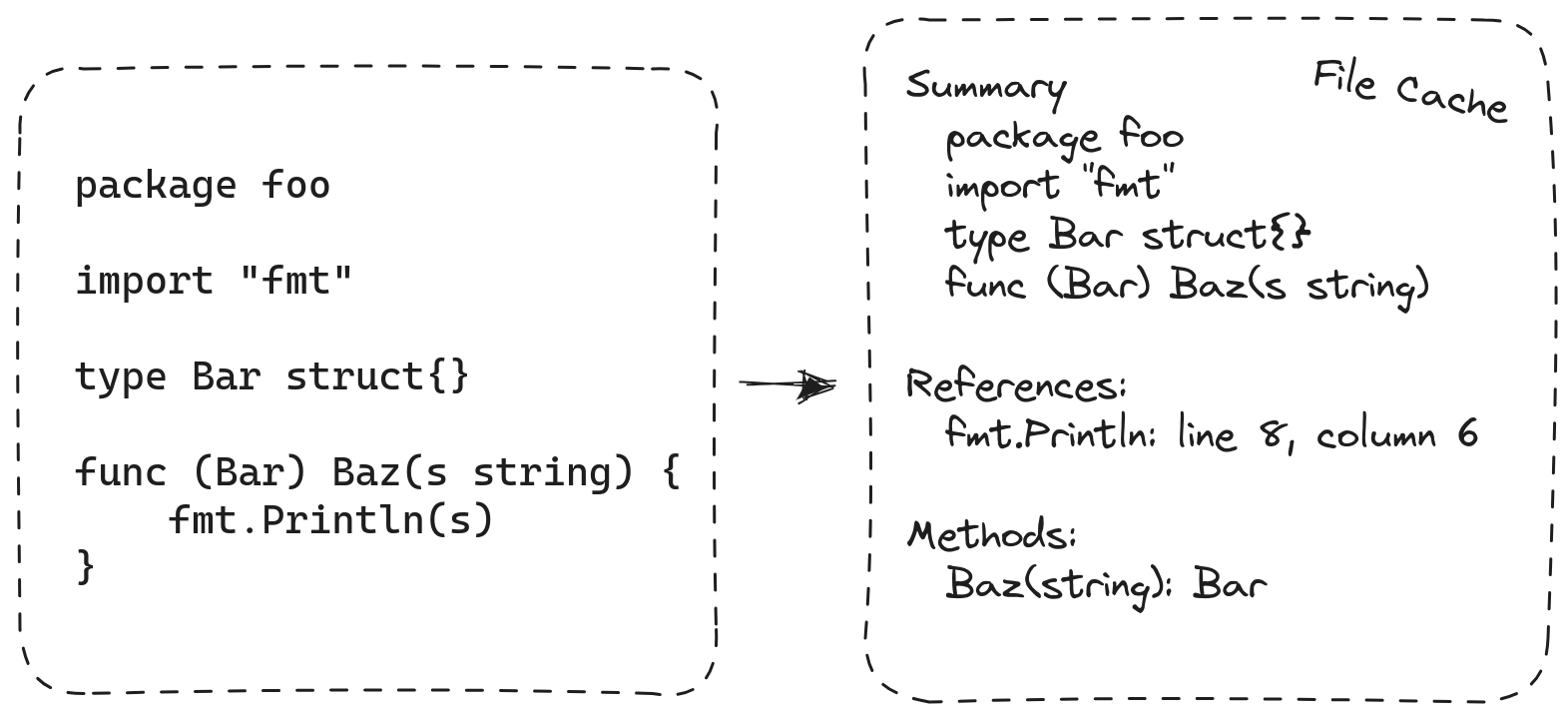
20 世纪 50 年代第一批编译器的设计者很快发现了单片编译的局限性。他们的解决方案是将程序分解成单元并分别编译每个单元。独立编译使得构建不适合内存的程序成为可能,通过分小块构建。在 Go 中,单元是包。不同包的编译不能完全分开:在编译包 P 时,编译器仍然需要关于 P 导入的包提供的信息。为了安排这一点,Go 构建系统会在 P 之前编译 P 的所有导入的包,Go 编译器会为每个包导出的 API 写入一个紧凑的摘要。P 的导入包的摘要作为 P 本身编译的输入。
Gopls v0.12 将独立编译引入 gopls,重用了编译器使用的相同包摘要格式。这个想法很简单,但细节之处存在微妙之处。我们重写了以前检查表示整个程序的_数据结构_的每个算法,使其现在一次处理一个包,并将每个包的结果保存到文件中,就像编译器发出目标代码一样。例如,查找函数的所有引用过去很简单,只需在程序数据结构中搜索特定指针值的所有出现。现在,当 gopls 处理每个包时,它必须构造并保存一个索引,将源代码中的每个标识符位置与它引用的符号名称关联起来。在查询时,gopls 加载并搜索这些索引。其他全局查询,例如“查找实现”,也使用类似的技术。
与 go build 命令一样,gopls 现在使用 基于文件的缓存 来存储从每个包计算出的信息摘要,包括每个声明的类型、交叉引用索引以及每个类型的_方法集_。由于缓存会在进程之间持久化,因此您会注意到第二次在工作区中启动 gopls 时,它会更快地准备好提供服务,如果您运行两个 gopls 实例,它们将协同工作。
此更改的结果是 gopls 的内存使用量与打开的包数量及其直接导入成正比。这就是我们在上图中观察到亚线性扩展的原因:随着存储库变大,任何一个打开的包所观察到的项目_比例_变小。
细粒度失效
当您在一个包中进行更改时,只需要重新编译直接或间接导入该包的包。这个想法是自 20 世纪 70 年代的 Make 以来所有增量构建系统的基础,gopls 自创建以来一直在使用它。实际上,LSP 启用编辑器中的每一次按键都会启动一个增量构建!然而,在一个大型项目中,间接依赖项会累加,导致这些增量重建速度过慢。事实证明,很多这项工作并非严格必需,因为大多数更改,例如在现有函数中添加语句,都不会影响导入摘要。
如果您在一个文件中进行小的更改,我们必须重新编译该包,但如果更改不影响导入摘要,我们就不必编译任何其他包。更改的效果被“修剪”了。影响导入摘要的更改需要重新编译直接导入该包的包,但大多数此类更改不会影响_那些_包的导入摘要,在这种情况下,效果仍然被修剪,并避免重新编译间接导入者。由于这种修剪,低级包中的更改很少需要重新编译_所有_间接依赖于该包的包。修剪的增量重建使工作量与每次更改的范围成正比。这不是一个新想法:它由 Vesta 引入,并且也用于 go build。
v0.12 版本将类似的修剪技术引入 gopls,更进一步,通过基于语法分析实现更快的修剪启发式。通过在内存中维护一个简化的符号引用图,gopls 可以快速确定包 c 中的更改是否可能通过引用链影响包 a。

在上例中,从 a 到 c 没有引用链,因此即使 a 间接依赖于 c,它也不会受到 c 中更改的影响。
新的可能性
虽然我们对取得的性能改进感到满意,但我们也对 gopls 的几项新功能感到兴奋,这些功能现在由于 gopls 不再受内存限制而变得可行。
首先是强大的静态分析。以前,我们的静态分析驱动程序必须操作 gopls 内存中的包表示,因此它无法分析依赖项:这样做会引入太多额外的代码。随着这一要求的解除,我们能够在 gopls v0.12 中包含一个新的分析驱动程序,该驱动程序分析所有依赖项,从而提高精度。例如,gopls 现在会报告 Printf 格式错误的诊断,即使是在您围绕 fmt.Printf 定义的自定义包装器中。值得注意的是,go vet 多年来一直提供这种级别的精度,但 gopls 在每次编辑后无法实时做到这一点。现在它能做到了。
第二个是 更简单的工作区配置和 对构建标签的改进处理。这两项功能都意味着 gopls 在您打开机器上的任何 Go 文件时都能“正常工作”,但如果没有优化工作,这两项功能都不可行(例如,每个构建配置都会成倍增加内存占用!)。
试用一下!
除了可扩展性和性能改进之外,我们还修复了 许多 已报告的 bug 以及许多未报告的 bug,这些 bug 是我们在转换过程中提高测试覆盖率时发现的。
安装最新的 gopls
$ go install golang.org/x/tools/gopls@latest
下一篇文章:Go 中的 WASI 支持
上一篇文章:Go 1.21 中的 Profile-guided 优化
博客索引