Go 博客
GIF 解码器:Go 接口练习
引言
在 2011 年 5 月 10 日于旧金山举行的 Google I/O 大会上,我们宣布 Go 语言现已在 Google App Engine 上可用。Go 是第一门在 App Engine 上提供的、可直接编译为机器码的语言,这使其成为 CPU 密集型任务(如图像处理)的理想选择。
有鉴于此,我们演示了一个名为 Moustachio 的程序,它可以轻松地改善类似下图这样的图片

通过添加胡子并分享结果

包括抗锯齿胡子渲染在内的所有图形处理,都由运行在 App Engine 上的 Go 程序完成。(源代码可在 appengine-go 项目中找到。)
尽管网络上的大多数图像(至少是可能需要添加胡子的图像)是 JPEG 格式,但还有无数其他格式在流传,Moustachio 接受几种上传格式似乎是合理的。Go 图像库中已存在 JPEG 和 PNG 解码器,但标志性的 GIF 格式却未被代表,因此我们决定及时编写一个 GIF 解码器以供发布。该解码器包含一些展示 Go 接口如何简化某些问题解决过程的片段。本文的其余部分将介绍其中几个实例。
GIF 格式
首先,快速浏览一下 GIF 格式。GIF 图像文件是**调色板化**的,也就是说,每个像素值都是文件中包含的固定颜色映射的索引。GIF 格式的出现是在显示器通常每个像素不超过 8 位数的时代,并且使用颜色映射将有限的数值集转换为照亮屏幕所需的 RGB(红、绿、蓝)三元组。(例如,这与 JPEG 不同,JPEG 没有颜色映射,因为编码单独表示不同的颜色信号。)
GIF 图像可以包含 1 到 8 位像素,包含边界,但 8 位像素是最常见的。
为简化起见,GIF 文件包含一个定义像素深度和图像尺寸的头部、一个颜色映射(8 位图像为 256 个 RGB 三元组),然后是像素数据。像素数据存储为一维比特流,使用 LZW 算法进行压缩,该算法对于计算机生成的图形非常有效,但对于摄影图像效果不佳。压缩后的数据然后被分解为长度分隔的块,每个块有一个字节计数(0-255),后跟该字节数的字节。
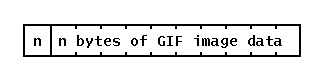
解块像素数据
要在 Go 中解码 GIF 像素数据,我们可以使用 `compress/lzw` 包中的 LZW 解压缩器。它有一个 `NewReader` 函数,该函数返回一个对象,该对象根据文档的说法,“通过解压缩从 r 读取的数据来满足读取请求”。
func NewReader(r io.Reader, order Order, litWidth int) io.ReadCloser
此处 `order` 定义了位打包顺序,`litWidth` 是以位为单位的字大小,对于 GIF 文件,它对应于像素深度,通常为 8。
但我们不能直接将输入文件作为第一个参数传递给 `NewReader`,因为解压缩器需要字节流,而 GIF 数据是块流,必须进行解包。为了解决这个问题,我们可以用一些解块代码包装输入 `io.Reader`,并使该代码再次实现 `Reader`。换句话说,我们将解块代码放入一个新类型(我们称之为 `blockReader`)的 `Read` 方法中。
这是 `blockReader` 的数据结构。
type blockReader struct {
r reader // Input source; implements io.Reader and io.ByteReader.
slice []byte // Buffer of unread data.
tmp [256]byte // Storage for slice.
}
读取器 `r` 将是图像数据的源,可能是文件或 HTTP 连接。`slice` 和 `tmp` 字段将用于管理解块。这是 `Read` 方法的完整代码。它是 Go 中切片和数组使用的一个很好的例子。
1 func (b *blockReader) Read(p []byte) (int, os.Error) {
2 if len(p) == 0 {
3 return 0, nil
4 }
5 if len(b.slice) == 0 {
6 blockLen, err := b.r.ReadByte()
7 if err != nil {
8 return 0, err
9 }
10 if blockLen == 0 {
11 return 0, os.EOF
12 }
13 b.slice = b.tmp[0:blockLen]
14 if _, err = io.ReadFull(b.r, b.slice); err != nil {
15 return 0, err
16 }
17 }
18 n := copy(p, b.slice)
19 b.slice = b.slice[n:]
20 return n, nil
21 }
第 2-4 行只是一个健全性检查:如果没有地方存放数据,则返回零。这永远不应该发生,但最好保持安全。
第 5 行通过检查 `b.slice` 的长度来询问上一次调用是否还有剩余数据。如果没有,切片长度将为零,我们需要从 `r` 读取下一个块。
GIF 块以字节计数开头,在第 6 行读取。如果计数为零,GIF 定义这是一个终止块,因此我们在第 11 行返回 `EOF`。
现在我们知道应该读取 `blockLen` 字节,因此我们将 `b.slice` 指向 `b.tmp` 的前 `blockLen` 字节,然后使用辅助函数 `io.ReadFull` 读取那么多字节。如果无法读取那么多字节,该函数将返回错误,这应该永远不会发生。否则,我们将准备好 `blockLen` 字节供读取。
第 18-19 行将数据从 `b.slice` 复制到调用者的缓冲区。我们正在实现 `Read`,而不是 `ReadFull`,因此我们允许返回少于请求的字节数。这很容易:我们只需将数据从 `b.slice` 复制到调用者的缓冲区(`p`),`copy` 函数的返回值就是传输的字节数。然后,我们重新切片 `b.slice` 以删除前 `n` 个字节,为下一次调用做好准备。
在 Go 编程中,将切片(`b.slice`)与数组(`b.tmp`)耦合是一个很好的技术。在这种情况下,这意味着 `blockReader` 类型的 `Read` 方法永远不会进行任何分配。这也意味着我们不需要保留一个计数器(它隐含在切片长度中),并且内置的 `copy` 函数确保我们永远不会复制超过我们应该复制的量。(有关切片的更多信息,请参阅Go 博客的这篇帖子。)
给定 `blockReader` 类型,我们只需像这样包装输入读取器(例如文件)即可解块图像数据流
deblockingReader := &blockReader{r: imageFile}
此包装将块分隔的 GIF 图像流转换为一个简单的字节流,该流可通过对 `blockReader` 的 `Read` 方法进行调用来访问。
连接各个部分
有了 `blockReader` 的实现以及库中可用的 LZW 压缩器,我们就拥有了解码图像数据流所需的所有部件。我们用这段来自代码的雷鸣般的声明将它们缝合在一起:
lzwr := lzw.NewReader(&blockReader{r: d.r}, lzw.LSB, int(litWidth))
if _, err = io.ReadFull(lzwr, m.Pix); err != nil {
break
}
就这样。
第一行创建一个 `blockReader` 并将其传递给 `lzw.NewReader` 来创建一个解压缩器。这里 `d.r` 是包含图像数据的 `io.Reader`,`lzw.LSB` 定义了 LZW 解压缩器中的字节顺序,`litWidth` 是像素深度。
给定解压缩器,第二行调用 `io.ReadFull` 来解压缩数据并将其存储在图像 `m.Pix` 中。当 `ReadFull` 返回时,图像数据已被解压缩并存储在图像 `m` 中,随时可以显示。
这段代码第一次就成功了。真的。
我们可以通过将 `NewReader` 调用放在 `ReadFull` 的参数列表中来避免临时变量 `lzwr`,就像我们在 `NewReader` 调用中构建 `blockReader` 一样,但这可能将过多的内容塞进了一行代码。
结论
Go 的接口使得通过像这样组合零件来构建软件变得容易,以重构数据。在此示例中,我们通过使用 `io.Reader` 接口将解块器和解压缩器链接在一起实现了 GIF 解码,这类似于类型安全的 Unix 管道。此外,我们将解块器作为 `Reader` 接口的一个(隐式)实现来编写,然后它不需要额外的声明或样板代码即可将其纳入处理管道。在大多数语言中,要如此简洁、干净且安全地实现此解码器都很困难,但在 Go 中,接口机制加上一些约定使其变得近乎自然。
这值得再来一张图,这次是一张 GIF 图

GIF 格式在 http://www.w3.org/Graphics/GIF/spec-gif89a.txt 上定义。
下一篇文章:聚焦 Go 外部库
上一篇文章:Google I/O 2011 Go 内容:视频
博客索引