Go 博客
迈向 Go 2
引言
[这是我今天在 Gophercon 2017 上的演讲稿,旨在邀请整个 Go 社区协助我们讨论和规划 Go 2。]
2007 年 9 月 25 日,在 Rob Pike、Robert Griesemer 和 Ken Thompson 讨论一种新的编程语言几天后,Rob 提出了“Go”这个名字。

第二年,Ian Lance Taylor 和我加入了团队,我们五人一起构建了两个编译器和一个标准库,最终于 2009 年 11 月 10 日开源发布。
在接下来的两年里,在新兴的 Go 开源社区的帮助下,我们尝试了大小各种的改动,完善了 Go,并于 2011 年 10 月 5 日提出了Go 1 的规划。

在 Go 社区的更多帮助下,我们修订并实施了该计划,并于 2012 年 3 月 28 日发布了 Go 1。

Go 1 的发布标志着近五年创意、疯狂努力的顶峰,我们将一个名称和一堆想法变成了一个稳定、可用于生产的语言。这也标志着从变革和动荡转向稳定的明确转变。
在 Go 1 发布之前的几年里,我们每周都在更改 Go,几乎破坏了所有人的 Go 程序。我们明白这阻碍了 Go 在生产环境中的使用,因为生产环境中的程序不能每周都重写以跟上语言的变化。正如宣布 Go 1 的博客文章所述,其根本驱动力在于为创建可靠的产品、项目和出版物(博客、教程、会议演讲和书籍)提供稳定的基础,让用户确信他们的程序将在未来几年内继续编译和运行而无需更改。
Go 1 发布后,我们知道我们需要花时间在 Go 的设计目标——生产环境中去使用它。我们明确地从进行语言更改转向在我们自己的项目中实际使用 Go 并改进实现:我们将 Go 移植到许多新系统,重写了几乎所有性能关键的部分以提高 Go 的运行效率,并添加了诸如竞态检测器之类的关键工具。
现在,我们有了五年使用 Go 构建大型、生产质量系统的经验。我们已经对什么有效、什么无效有了体会。现在是时候开始 Go 演进和增长的下一步,规划 Go 的未来了。我今天来到这里,是想请在座的各位 Go 社区成员,无论您是在 GopherCon 的观众席上,还是在观看视频,或者稍后阅读 Go 博客,在我们规划和实现 Go 2 时,请与我们一起努力。
在本次演讲的剩余部分,我将解释 Go 2 的目标;约束和限制;整体流程;撰写我们使用 Go 的经验的重要性,特别是它们与我们可能试图解决的问题的关系;可能的解决方案类型;我们如何交付 Go 2;以及你们所有人如何提供帮助。
目标
我们今天对 Go 的目标与 2007 年相同。我们希望提高程序员在管理两种规模方面的效率:生产规模,尤其是与许多其他服务器交互的并发系统,如今以云软件为代表;以及开发规模,尤其是由许多工程师松散协调的大型代码库,如今以现代开源开发为代表。
这些规模会在各种规模的公司中出现。即使是一家五人的初创公司,也可能使用其他公司提供的庞大的基于云的 API 服务,并使用比自己编写的软件更多的开源软件。生产规模和开发规模对于这家初创公司来说,与在 Google 一样重要。
Go 2 的目标是解决 Go 在规模化方面最显著的不足之处。
(关于这些目标的更多信息,请参阅 Rob Pike 2012 年的文章“Go at Google: Language Design in the Service of Software Engineering”和我 2015 年 GopherCon 的演讲“Go, Open Source, Community”。)
约束
Go 的目标自始至终未变,但 Go 的约束条件肯定已经改变。最重要的约束是现有的 Go 用法。我们估计全球有至少五十万 Go 开发者,这意味着有数百万个 Go 源文件和至少十亿行 Go 代码。这些程序员和源代码代表了 Go 的成功,但它们也是 Go 2 的主要约束。
Go 2 必须能够兼容所有这些开发者。我们必须要求他们放弃旧习惯、学习新习惯,但前提是回报巨大。例如,在 Go 1 之前,错误类型实现的方法名为 String。在 Go 1 中,我们将其重命名为 Error,以区分错误类型和其他可以自我格式化的类型。前几天我在实现一个错误类型时,不假思索地将其方法命名为 String 而不是 Error,这当然无法编译。五年后,我还没有完全改掉旧习惯。这种澄清性的重命名是 Go 1 中一个重要的改变,但如果没有非常充分的理由,对 Go 2 来说过于颠覆。
Go 2 还必须兼容所有现有的 Go 1 源代码。我们绝不能分裂 Go 生态系统。混合程序,即 Go 2 编写的包导入 Go 1 编写的包,反之亦然,在长达数年的过渡期内必须无缝工作。我们将不得不弄清楚具体如何做到这一点;像 go fix 这样的自动化工具肯定会发挥作用。
为了最大限度地减少干扰,每个更改都需要仔细思考、规划和工具支持,这反过来又限制了我们可以进行的更改数量。也许我们可以做两三个,肯定不会超过五个。
我不包括小的维护性更改,例如允许更多口语化语言中的标识符或添加二进制整数文字。这些小的更改也很重要,但更容易正确实现。我今天关注的是可能发生的重大更改,例如对错误处理的额外支持,或者引入不可变或只读值,或者添加某种形式的泛型,或其他尚未提出的重要主题。我们只能做其中少数重大更改。我们将不得不谨慎选择。
流程
这就引出了一个重要问题。开发 Go 的流程是什么?
在 Go 的早期,只有我们五个人时,我们在一对相邻的共享办公室里工作,中间隔着一扇玻璃墙。很容易把每个人都叫到一个办公室讨论某个问题,然后回到各自的工位实现解决方案。在实现过程中出现一些曲折时,很容易再次召集大家。Rob 和 Robert 的办公室里有一个小沙发和一个白板,所以通常我们会有人进去在白板上写一个例子。通常等例子写完时,其他人也都在自己的工作中找到了合适的停顿点,准备坐下来讨论。这种非正式的沟通方式显然无法适应如今全球化的 Go 社区。
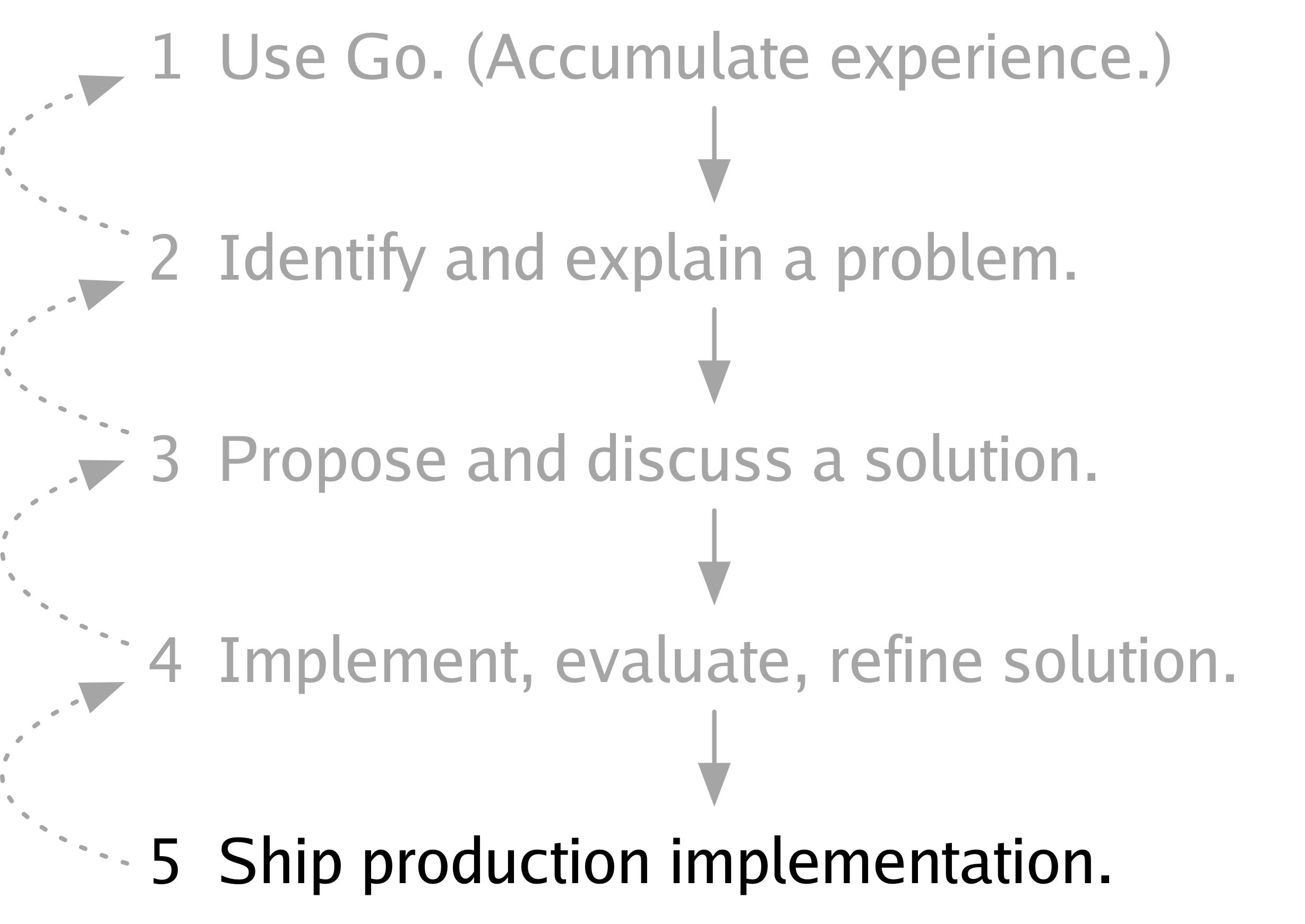
自 Go 开源发布以来,我们的一部分工作就是将我们的非正式流程移植到更正式的邮件列表、问题跟踪器和五十万用户环境中,但我认为我们从未明确描述过我们的整体流程。有可能我们从未有意识地考虑过它。然而,回顾过去,我认为这是我们 Go 工作的基本框架,是我们自第一个原型运行以来一直遵循的流程。
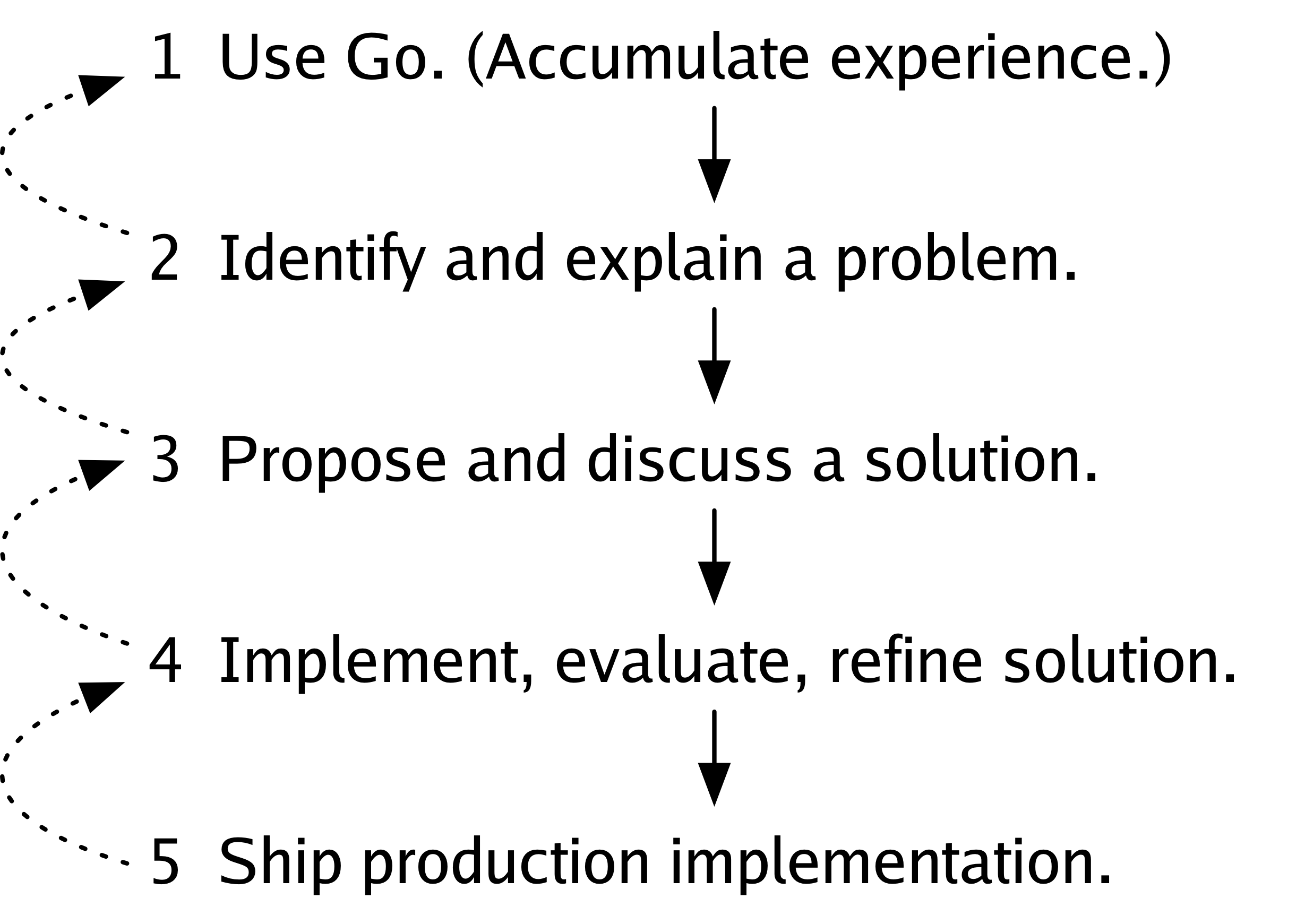
第一步是使用 Go,积累使用经验。
第二步是识别 Go 中可能需要解决的问题并将其阐明,向他人解释,写下来。
第三步是提出问题的解决方案,与他人讨论,并根据讨论修改解决方案。
第四步是实现解决方案,评估它,并根据评估进行改进。
最后,第五步是交付解决方案,将其添加到语言、库或人们日常使用的工具集中。
对于一个特定的更改,不必由同一个人完成所有这些步骤。事实上,通常有许多人合作完成任何一个步骤,并且可能为同一个问题提出许多解决方案。此外,在任何时候,我们都可能意识到我们不想继续推进某个想法,并回到前面的步骤。
虽然我认为我们从未将这个流程作为一个整体来谈论过,但我们解释过其中的一部分。2012 年,当我们发布 Go 1 并说现在是时候使用 Go 而不是更改它时,我们是在解释第一步。2015 年,当我们引入 Go 更改提案流程时,我们是在解释第三、第四和第五步。但我们从未详细解释过第二步,所以我想现在来做这件事。
(关于 Go 1 的开发以及从语言更改转向其他方面的更多信息,请参阅 Rob Pike 和 Andrew Gerrand 2012 年 OSCON 的演讲“The Path to Go 1”。关于提案流程的更多信息,请参阅 Andrew Gerrand 2015 年 GopherCon 的演讲“How Go was Made”以及提案流程文档。)
解释问题
解释问题有两个部分。第一部分——也是比较容易的部分——是准确说明问题是什么。我们开发者在这方面做得相当好。毕竟,我们写的每一个测试都是一个需要解决的问题的陈述,语言精确到连计算机都能理解。第二部分——也是比较难的部分——是充分描述问题的意义,以便每个人都能理解为什么我们应该花时间解决它并维护解决方案。与精确陈述问题不同,我们不需要经常描述问题的意义,而且我们在这方面做得远不如在陈述问题上。计算机从不问我们“这个测试用例为什么重要?你确定这就是你需要解决的问题吗?解决这个问题是你现在能做的最重要的事情吗?”也许有一天会的,但不是今天。
让我们来看一个 2011 年的旧例子。这是我在规划 Go 1 时写下关于将 os.Error 重命名为 error.Value 的内容。

它以一个精确的、单行的陈述开始:在非常底层的库中,所有东西都导入“os”来使用 os.Error。然后有五行,我在这里用下划线标出,用于描述问题的意义:被“os”使用的包无法在自己的 API 中呈现错误,而其他包依赖“os”的原因与操作系统服务无关。
这五行话能让你相信这个问题很重要吗?这取决于你能多好地填补我省略的上下文:被理解需要预测他人需要知道什么。对我当时的目标受众——在 Google 阅读该文档的另外十位 Go 团队成员——来说,这五十个词就足够了。为了将同样的问题呈现给去年秋天 GothamGo 的观众——一个背景和专业领域更加多样化的观众——我需要提供更多的上下文,我使用了大约两百个词,加上真实的代码示例和图表。当今全球化的 Go 社区的一个事实是,描述任何问题的意义都需要添加上下文,特别是通过具体的例子来说明,而当你与同事交谈时,你会省略这些。
说服他人问题的重要性是一个至关重要的步骤。当一个问题显得微不足道时,几乎所有解决方案都会显得过于昂贵。但对于一个重要的问题,通常有很多成本合理的解决方案。当我们不同意采纳某个特定解决方案时,我们实际上可能是在不同意所解决问题的意义。这一点非常重要,我想回顾两个最近的例子,至少事后看来,它们清晰地展示了这一点。
示例:闰秒
我的第一个例子是关于时间的。
假设你想测量一个事件需要多长时间。你记下开始时间,运行事件,记下结束时间,然后从结束时间中减去开始时间。如果事件持续了十毫秒,减法的结果就是十毫秒,可能加上或减去一个小的测量误差。
start := time.Now() // 3:04:05.000
event()
end := time.Now() // 3:04:05.010
elapsed := end.Sub(start) // 10 ms
这种明显的程序在闰秒期间会失败。当我们的时钟与地球的每日自转不太同步时,会在午夜前插入一个闰秒——正式为晚上 11:59 和 60 秒。与闰年不同,闰秒没有可预测的模式,这使得它们难以融入程序和 API。操作系统通常通过在午夜前将时钟回拨一秒来实现闰秒,而不是试图表示偶尔出现的 61 秒分钟,这样晚上 11:59 和 59 秒就会出现两次。这个时钟重置使得时间看起来是倒退的,所以我们十毫秒的事件可能会被计时为负 990 毫秒。
start := time.Now() // 11:59:59.995
event()
end := time.Now() // 11:59:59.005 (really 11:59:60.005)
elapsed := end.Sub(start) // –990 ms
由于日时钟在这样的时钟重置期间不适用于计时事件,操作系统现在提供第二个时钟,即单调时钟,它没有绝对意义但会计算秒数且永不重置。
除了奇数次时钟重置之外,单调时钟并不比日时钟好,而日时钟的好处是它有助于报时,所以为了简洁起见,Go 1 的时间 API 只暴露了日时钟。
2015 年 10 月,一个bug 报告指出,Go 程序无法在时钟重置(尤其是典型的闰秒)期间正确计时事件。建议的修复也是最初的 issue 标题:“添加一个新的 API 来访问单调时钟源”。我争辩说,这个问题不够重要,不值得新增 API。几个月前,对于 2015 年中期的闰秒,Akamai、Amazon 和 Google 在一整天内都微调了时钟,用平滑的方式吸收了额外的一秒,而没有回拨时钟。这似乎预示着这种“闰秒平滑”方法的最终广泛采用将消除闰秒时钟重置作为生产系统上的问题。相比之下,在 Go 中添加新 API 会带来新问题:我们需要解释两种时钟,教育用户何时使用哪种时钟,以及转换许多现有的代码行,这一切都是为了一个很少发生且可能自行消失的问题。
当出现没有明确解决方案的问题时,我们总是那样做:等待。等待让我们有更多时间来积累经验和理解问题,也有更多时间找到一个好的解决方案。在这种情况下,等待增加了我们对问题重要性的理解,形式是一次幸运地微小的Cloudflare 的故障。他们的 Go 代码将 2016 年末闰秒期间的 DNS 请求计时为大约负 990 毫秒,导致其服务器同时发生恐慌,在高峰期中断了 0.2% 的 DNS 查询。
Cloudflare 正是 Go 所针对的那种云系统,而且由于 Go 无法正确计时事件而导致了生产故障。然后,关键在于,Cloudflare 在一篇题为“How and why the leap second affected Cloudflare DNS”的博客文章中报告了他们的经验。通过分享他们在生产环境中 Go 使用的具体细节,John 和 Cloudflare 帮助我们理解了,准确计时跨闰秒时钟重置的问题过于重要,不能置之不理。在那篇文章发布两个月后,我们设计并实现了一个解决方案,该解决方案将在 Go 1.9 中发布(实际上,我们是没有新增 API 完成的)。
示例:别名声明
我的第二个例子是 Go 对别名声明的支持。
在过去的几年里,Google 成立了一个专注于大规模代码更改的团队,意味着 API 迁移和 Bug 修复应用于我们用 C++、Go、Java、Python 等语言编写的数百万源文件和数十亿行代码的代码库。我从该团队的工作中学到的一件事是,当将 API 从一个名称更改为另一个名称时,能够分多步更新客户端代码,而不是一次性完成,这一点非常重要。要做到这一点,必须能够编写一个声明,将对旧名称的使用转发到新名称。C++ 有 #define、typedef 和 using 声明来实现这种转发,但 Go 没有。当然,Go 的目标之一是能够很好地扩展到大型代码库,随着 Google 中 Go 代码量的增长,变得很清楚我们需要某种形式的转发机制,并且其他项目和公司也会在它们的 Go 代码库增长时遇到这个问题。
2016 年 3 月,我开始与 Robert Griesemer 和 Rob Pike 讨论 Go 如何处理渐进式代码库更新,我们得出了别名声明,它们正是所需的转发机制。此时,我对 Go 的发展方向感觉非常好。我们从 Go 的早期就开始讨论别名——事实上,第一个规范草案中有一个使用别名声明的例子——但每次我们讨论别名,以及后来的类型别名时,我们都没有明确的用例,所以我们没有包含它们。现在我们提议添加别名,不是因为它们是一个优雅的概念,而是因为它们解决了 Go 在满足可扩展软件开发目标方面的一个重要实际问题。我希望这能为 Go 的未来变化提供一个模型。
春季晚些时候,Robert 和 Rob 编写了提案,Robert 在 2016 年 Gophercon 的闪电演讲中进行了演示。接下来的几个月并不顺利,而且绝对不是 Go 未来变化的榜样。我们学到的许多教训之一是描述问题的重要性。
一分钟前,我向你们解释了这个问题,提供了一些关于它如何产生以及为什么产生的背景信息,但没有具体的例子可以帮助你们评估这个问题是否会在某个时候影响到你们。去年夏天的提案和闪电演讲给出了一个抽象的例子,涉及包 C、L、L1 和 C1 到 Cn,但没有开发者可以联系的具体例子。结果,社区的大部分反馈都基于别名只解决了 Google 问题,而不是其他人的问题。
就像我们在 Google 最初不理解正确处理闰秒时间重置的重要性一样,我们也未能有效地向更广泛的 Go 社区传达在大型代码更改期间处理渐进式代码迁移和修复的重要性。
秋天我们重新开始。我做了一个演讲并写了一篇文章,展示了这个问题,使用了来自开源代码库的多个具体示例,说明这个问题在何处都会出现,不仅仅是在 Google 内部。现在更多人理解了这个问题并能看到其重要性,我们进行了一次富有成效的讨论,关于哪种解决方案最好。结果是类型别名将包含在 Go 1.9 中,并将有助于 Go 扩展到越来越大的代码库。
经验报告
这里的教训是,以一种在不同环境中工作的人能够理解的方式描述问题的意义是困难但至关重要的。为了在社区中讨论 Go 的重大更改,我们将需要特别关注描述我们想要解决的任何问题的意义。最清晰的方法是展示问题如何影响实际程序和实际生产系统,就像在Cloudflare 的博客文章和我的重构文章中一样。
像这样的经验报告将抽象问题转化为具体问题,并帮助我们理解其意义。它们也充当测试用例:任何提出的解决方案都可以通过检查它对报告所描述的实际、真实世界问题的实际影响来评估。
例如,我最近在研究泛型,但我脑海中没有对 Go 用户需要泛型来解决的详细、具体问题的清晰图景。因此,我无法回答诸如是否支持泛型方法的设计问题,即方法独立于接收者进行参数化。如果我们有大量真实用例,我们可以通过检查重要的用例来开始回答这样的问题。
再举个例子,我看到过各种扩展错误接口的提案,但我没有看到任何经验报告显示大型 Go 程序如何尝试理解和处理错误,更不用说显示当前的错误接口如何阻碍这些尝试了。在解决问题之前,这些报告将帮助我们所有人都更好地理解问题的细节和重要性。
我还可以继续说下去。Go 的每一个潜在的重大更改都应该由一个或多个经验报告来驱动,这些报告记录了人们今天如何使用 Go 以及为什么这不够好。对于我们可能考虑的明显的重大更改,我不了解有多少此类报告,特别是没有用真实世界示例来说明的报告。
这些报告是 Go 2 提案流程的原材料,我们需要你们所有人来撰写它们,以帮助我们理解你们在 Go 方面的经验。你们有五十万人,在各种各样的环境中工作,而我们却没那么多。在您自己的博客上写一篇文章,或者写一篇Medium帖子,或者写一个GitHub Gist(为 Markdown 添加 .md 文件扩展名),或者写一个Google 文档,或者使用您喜欢的任何其他发布机制。发布后,请将帖子添加到我们的新 wiki 页面 golang.org/wiki/ExperienceReports。
解决方案
既然我们知道如何识别和解释需要解决的问题,我想简要说明一点,并非所有问题都最好通过语言更改来解决,这没关系。
我们可能想解决的一个问题是,计算机通常可以在基本的算术运算中计算出附加结果,但 Go 不提供对这些结果的直接访问。2013 年,Robert 提议我们可以将双结果(“comma-ok”)表达式的想法扩展到基本算术运算。例如,如果 x 和 y 是,比如说,uint32 值,lo, hi = x * y 不仅会返回通常的低 32 位,还会返回乘积的高 32 位。这个问题似乎并不特别重要,所以我们记录了潜在的解决方案但没有实现。我们等待着。
最近,我们为 Go 1.9 设计了一个math/bits 包,其中包含各种位操作函数
package bits // import "math/bits"
func LeadingZeros32(x uint32) int
func Len32(x uint32) int
func OnesCount32(x uint32) int
func Reverse32(x uint32) uint32
func ReverseBytes32(x uint32) uint32
func RotateLeft32(x uint32, k int) uint32
func TrailingZeros32(x uint32) int
...
该包对每个函数都有很好的 Go 实现,但编译器也会在可用时替换特殊的硬件指令。基于 math/bits 的经验,Robert 和我都认为通过更改语言来提供附加的算术结果是不明智的,而应该在 math/bits 这样的包中定义适当的函数。这里最好的解决方案是库更改,而不是语言更改。
另一个我们可能想解决的问题是,在 Go 1.0 之后,goroutine 和共享内存使得在 Go 程序中引入竞态变得过于容易,导致生产环境崩溃和其他行为异常。基于语言的解决方案是找到某种方法来禁止数据竞态,使编写甚至编译一个存在数据竞态的程序成为不可能。如何在像 Go 这样的语言中实现这一点仍然是编程语言世界中的一个悬而未决的问题。相反,我们在主发行版中添加了一个工具,并使其易于使用:这个工具,即竞态检测器,已经成为 Go 体验不可或缺的一部分。这里最好的解决方案是运行时和工具链更改,而不是语言更改。
当然,也会有语言更改,但并非所有问题都最好在语言层面解决。
发布 Go 2
最后,我们将如何发布和交付 Go 2?
我认为最好的计划是,将 Go 2 的向后兼容部分通过 Go 1 的发布序列,增量地、逐个功能地发布。这有几个重要的优点。首先,它使 Go 1 的发布保持正常的时间表,继续提供用户现在依赖的及时 Bug 修复和改进。其次,它避免了在 Go 1 和 Go 2 之间分割开发精力。第三,它避免了 Go 1 和 Go 2 之间的分歧,以缓和最终的所有迁移。第四,它允许我们一次专注于一个更改并交付它,这应该有助于保持质量。第五,它将鼓励我们设计向后兼容的功能。
在任何更改开始进入 Go 1 版本之前,我们需要时间进行讨论和规划,但对我来说,似乎有可能我们在一年左右后开始看到一些小的更改,大约是 Go 1.12。这也给了我们时间先支持包管理。
一旦所有向后兼容的工作完成,例如在 Go 1.20 中,我们就可以在 Go 2.0 中进行向后不兼容的更改。如果最终没有向后不兼容的更改,也许我们只需宣布 Go 1.20 就是 Go 2.0。无论哪种方式,届时我们将从 Go 1.X 版本序列的开发过渡到 Go 2.X 序列的开发,也许为最后的 Go 1.X 版本提供一个扩展的支持窗口。
这一切都有些推测性,我刚才提到的具体版本号只是粗略估计的占位符,但我想明确的是,我们不会放弃 Go 1,事实上,我们将尽可能地保留 Go 1。
寻求帮助
我们需要您的帮助。
Go 2 的对话从今天开始,将在公开场合,在邮件列表和问题跟踪器等公共论坛上进行。请在每一步都帮助我们。
今天,我们最需要的是经验报告。请告诉我们 Go 对您来说如何奏效,更重要的是,如何不奏效。写一篇博文,包含真实示例、具体细节和真实经历。并在我们的wiki 页面上链接它。这就是我们将开始讨论我们 Go 社区可能想改变 Go 的地方。
谢谢。
下一篇文章:贡献者峰会
上一篇文章:引入开发者体验工作组
博客索引